Bloom filter
1 개념
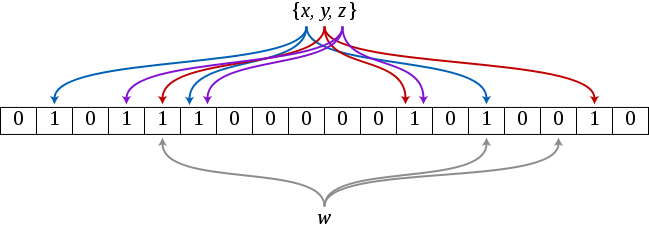
해시 함수로 생긴 값들을 임의의 테이블의 인덱스 값에 대응 시켜서 그 값이 0인지 1인지만을 따지는 자료구조.
해시 함수는 기본적으로 충돌의 가능성이 있기에 블룸 필터에는 긍정 오류[1]의 가능성이 있다. 다만 반대로 부정 오류의 가능성은 없다.
해시 함수들을 기본적으로 여러개를 가지는데 임의의 테이블의 크기, 넣어야 하는 자료의 크기, 해시 함수의 수에 따라 오류의 확률이 정해진다.
그래서 요구하는 긍정 오류율이 있다면 넣어야 하는 자료의 크기를 고려해서 테이블의 크기와 해시 함수의 수를 정하는 편.
여기 까지 읽었으면 알겠지만 있는지 없는지 만을 보는 그 특성 때문에 삽입만 가능하고 제거가 안된다.(...)
2 구현
사실 알고리즘 자체는 매우 간단하기 때문에 구현에 머리를 싸맬 필요가 없다. 삽입 시엔 그냥 여러개의 해시 함수를 준비하고 들어오는 값에 대해 해시 값을 여러개를 만든 다음, 그 값을 테이블의 인덱스에 대응시켜 1로 바꿔버리면 끝. 사실 이걸 삽입이라 불러야 할지 말아야 할지... 값의 확인의 경우에도 마찬가지로 하고 1인지만 확인하는거로 바꾸면 구현 끝.
3 활용
이거 활용 가능해요? 이게 자료 구조인지 의심이 되는데
자료구조의 특성 때문에 활용 자체에 의문이 들 수 있지만, 알고리즘을 보라. 얼마나 간단한가. 그 간단함때문에 쓰일 수 있다. 즉 매우 빠르다. 오류가 나도 그렇게 문제가 되는 상황이 아니라면 충분히 쓸 수 있다는것.
구체적인 예로는 구글 크롬은 악의적인 URL을 확인할 때 바로 이 블룸 필터를 사용한다. 또 맞춤법 검사기의 경우 이 블룸 필터가 쓰이기도 한다.
4 그 외
제거가 안된다는 매우 기묘한 특성 때문에 블룸 필터에 제거 기능을 더한 자료 구조가 만들어 졌다. 다만 블룸 필터라 부르지 않고 카운팅 필터라고 불린다.- ↑ 쉽게 말해 넣은 적 없는 값에 대해 있다고 하는 경우. 그 반대인 부정 오류는 넣은 적 있는데 없다고 하는 겅우.