1 개요
영어 : Machine Learning (머신 러닝)
인공지능의 대표적인 방법이었던 전문가 시스템은 사람이 직접 많은 수의 규칙을 집어넣는 것을 전제로 하였다. 이같은 접근 방법은 과학에 기반한 학문들, 예를들어 의학이나 생물 분야에서는 큰 역할을 할 수 있었다. 의사들의 진단을 도와주는 전문가 시스템에 기반한 프로그램을 생각해보면 인간이 지금까지 발견한 의학적인 규칙들을 데이터베이스화 하여 등록시켜주면 되는 것이었다.
하지만, 시간이 지남에 따라 세상은 사람조차 스스로 어떻게 하는지 모르는 영역을 요구하기 시작했다. 대표적으로 음성인식을 들 수 있겠다. 애플의 시리 같은 프로그램을 만든다고 생각해보자. 일단 사람이 어떤 문장을 말했는지 소리 → 알파벳으로 알아들을 수 있어야 하며, 알파벳으로 이루어진 그 문장이 어떠한 의미를 갖는지 해석할 수 있어야 한다. 이 같은 시스템은 사람이 하나하나 규칙을 만들어 준다고 형성될 수 있지 않다. 소리 같은 경우에는 컴퓨터에 PCM의 형태로 전달이 되는데 대체로 이는 1초에 최소 나무위키 항목 하나 분량의 데이터를 포함하고 있다. 절대로 "열이 많이 나고 오한이 있고 구토증상이 있으므로 독감이다"라는 쉬운 조건부로 해결될 문제가 아닌 것이다. 전체적인(오차가 존재하며 거대한) 데이터를 보고 그것이 의미하는 정보들을 명확히 짚어낼 줄 알아야 한다.
그리하여 나온 방법이 기계학습이다. 이름에서 알 수 있듯이 기계학습은 기계, 즉 컴퓨터를 인간처럼 학습시켜 스스로 규칙을 형성할 수 있지 않을까 하는 시도에서 비롯되었다. 주로 통계적인 접근 방법을 사용하는데, 위의 독감의 예와 반대로 "독감이 걸린 사람은 대부분 열이 많이 나고 오한이 있고 구토 증상이 있었다"라는 통계에 기반하여 독감을 진단하는 것이다. 예시를 보면 알 수 있듯이 이는 인간이 하는 추론 방식과 유사하고 매우 강력하다.
기계학습의 발전으로 인해 현재의 거의 모든 시스템(인공지능, 검색엔진, 광고, 마케팅, 로봇, 인사활동, 등등)은 기계학습의 방법론 없이는 정상적으로 가동되지 않게 되었다.
2 선수과목
기계학습을 공부하고자 하면 기본적으로 컴퓨터과학과에서 다루는 대부분의 수학 과목을 필요로 한다. 대표적으로
등이 있다. 그렇다고 이 수학과목들을 전부 전문가 수준으로 익힐 필요는 없고 기계학습의 방법론을 이해하고 그곳에 적용할 수 있는 스킬을 기르는 것이 무엇보다 중요하다.
또, 기계학습 알고리즘을 배웠을 때 그것을 구현하는 데 필요한 프로그래밍 언어도 알아야 한다. 대표적으로 3가지를 들자면, R 언어는 현재 가장 많이 쓰이는 통계 기반 프로그래밍 언어이다. R 언어의 강점은 간단한 코딩으로 충분히 인지 가능할 정도로 시각화된 데이터를 얻어내는 것에 있다. 이를 통해 개발 파이프라인을 단축시키는데 많은 기여를 한다. 또, 파이썬은 R 언어에 이어 이 분야에서 두 번째로 많이 쓰이는 언어이며, numpy 라이브러리를 써서 기계학습 알고리즘을 코딩하도록 도와준다. 비록 R 언어보다 코딩에 다소 시간이 걸리지만, 파이썬 언어의 대표적 장점인 이식성이 있어 다양한 분야에서 사용되어지며, Scipy 라이브러리 등을 추가하여 내부 변수의 계산을 하거나 Cython 등을 이용하여 알고리즘의 속도를 빠르게 하기에도 용이하다. 마지막으로 Matlab이 있는데 아무래도 수학적 정밀도가 어느 정도 보장되는 언어이다보니 주로 연구실 등에서 사용되어진다.
3 정의
기계학습의 가장 그럴듯한 정의는 다음과 같다. 이는 "Machine Learning" 책을 지은 CMU의 교수 Tom M. Mitchell이 제시한 것이다.
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E"
즉, 어떠한 태스크(T)에 대해 꾸준한 경험(E)을 통하여 그 T에 대한 성능(P)를 높이는 것, 이것이 기계학습이라고 할 수 있다.
정의에서 알 수 있듯이, 기계학습에서 가장 중요한 것은 E에 해당하는 데이터이다. 좋은 품질의 데이터를 많이 가지고 있다면 보다 높은 성능을 끌어낼 수 있다.
3.1 기능
기계학습으로 할 수 있는 기능엔 크게 두 가지가 있다.
- 분류 (Classification) : 주어진 입력 x의 레이블 y를 추정해내는 것
- y는 1/0의 이진값이거나 혹은 확률이나 실수값으로 주어질 수 있다. 미소녀 이미지를 주었을 때 안경을 끼고 있는지 아닌지(이진값) 분류하거나 혹은 얼마나 어린지(확률값) 분류할 때 사용된다.
- 군집화 (Clustering) : 주어진 입력 x와 비슷한 입력들의 군집(cluster)을 추정해내는 것
- 미소녀 이미지를 1만장 정도 주고 머리색을 기준으로 군집화 하라고 할 경우가 속할 수 있다. 이 때 머리색의 기준을 특정한 RGB 값으로 줄 수도 있지만, 알고리즘에 따라 자체적으로 학습을 통해 기준을 설정할 수 있게 할 수도 있다.
왜 다 미소녀냐
3.2 학습방법
기계학습의 학습 방법엔 크게 3가지가 있다.
특히, 레이블(lable)의 유무에 따라 지도학습과 비지도학습으로 나뉘는데, 여기서 레이블이란, 학습 데이터의 속성을 무엇을 분석할 지에 따라 정의되는 데이터를 뜻한다.
- 지도 학습(Supervised Learning) : 사람이 교사로써 각각의 입력(x)에 대해 레이블(y)을 달아놓은 데이터를 컴퓨터에 주면 컴퓨터가 그것을 학습하는 것이다. 사람이 직접 개입하므로 정확도가 높은 데이터를 사용할 수 있다는 장점이 있다. 대신에 사람이 직접 레이블을 달아야 하므로 인건비 문제가 있고, 구할 수 있는 데이터양도 적다는 문제가 있다. 크게 분류(Classification)과 회귀(Regression) 로 나눌 수 있다.
- 분류(Classification): 레이블 y가 이산적(Discrete)인 경우 즉, y가 가질 수 있는 값이 [0,1,2 ..]와 같이 유한한 경우 분류, 혹은 인식 문제라고 부른다. 일상에서 가장 접하기 쉬우며, 연구가 많이 되어있고, 기업들이 가장 관심을 가지는 문제 중 하나다. 아래와 같은 예시가 있다.
- 주차게이트에서 번호판 인식: 요새 주차장들은 티켓을 뽑지 않고, 차량 번호판을 찍어서 글자를 인식한다. x가 이미지 픽셀 값들이고, y가 글자인 경우.
- 페이스북이나 구글 포토의 얼굴 인식: 페이스북에 사진을 올리면 친구 얼굴 위에 이름이 자동으로 달리고는 하는데, 이것 역시 기계학습을 이용한 것. x가 이미지 픽셀, y가 사람 이름인 경우.
- 음성 인식: 음성 wav 파일에 대해서 해당 wav 부분이 어떤 음절인지를 인식하는 것. 애플 시리, 구글 보이스 등에서 사용된다(질문에 대해서 답해주는 부분 말고, 인식 부분만). x가 음성 파형, y가 음절.
- 대표적으로 KNN, 서포트 벡터 머신(SVM) 그리고 의사결졍 트리 모델이 대표적이다.
- 회귀(Regression): 레이블 y가 실수인 경우 회귀문제라고 부른다. 보통 엑셀에서 그래프 그릴 때 많이 접하는 바로 그것이다. 데이터들을 쭉 뿌려놓고 이것을 가장 잘 설명하는 직선 하나 혹은 이차함수 곡선 하나를 그리고 싶을 때 회귀기능을 사용한다. 잘 생각해보면 데이터는 입력(x)와 실수 레이블(y)의 짝으로 이루어져있고, 새로운 임의의 입력(x)에 대해 y를 맞추는 것이 바로 직선 혹은 곡선이므로 기계학습 문제가 맞다.
- 분류(Classification): 레이블 y가 이산적(Discrete)인 경우 즉, y가 가질 수 있는 값이 [0,1,2 ..]와 같이 유한한 경우 분류, 혹은 인식 문제라고 부른다. 일상에서 가장 접하기 쉬우며, 연구가 많이 되어있고, 기업들이 가장 관심을 가지는 문제 중 하나다. 아래와 같은 예시가 있다.
- 비지도 학습(Unsupervised Learning) : 사람 없이 컴퓨터가 스스로 레이블 되어 있지 않은 데이터에 대해 학습하는 것. 즉 y없이 x만 이용해서 학습하는 것이다. 정답이 없는 문제를 푸는 것이므로 학습이 맞게 됐는지 확인할 길은 없지만, 인터넷에 있는 거의 모든 데이터가 레이블이 없는 형태로 있으므로 앞으로 기계학습이 나아갈 방향으로 설정되어 있기도 하다. 군집화(Clustering)이 대표적인 예다.
- 군집화(Clustering): 데이터가 쭉 뿌려져 있을 때 레이블이 없다고 해도 데이터간 거리에 따라 대충 두 세개의 군집으로 나눌 수 있다. 이렇게 x만 가지고 군집을 학습하는 것이 군집화이다.
- 분포 추정(Underlying Probability Density Estimation): 군집화에서 더 나아가서, 데이터들이 쭉 뿌려져 있을 때 얘네들이 어떤 확률 분포에서 나온 샘플들인지 추정하는 문제이다.
- 강화 학습(Reinforcement Learning) : 위의 두 문제의 분류는 지도의 여부에 따른 것이었는데, 강화학습은 조금 다르다. 강화학습은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것이다. 행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습이 진행된다. 그리고 이러한 보상은 행동을 취한 즉시 주어지지 않을 수도 있다(지연된 보상). 이 때문에 문제의 난이도가 앞의 두개에 비해 대폭 상승한다. 대표적으로 게임 인공지능을 만드는 것을 생각해볼 수 있다. 체스에서 현재 나와 적의 말의 배치가 State가 되고 여기서 어떤 말을 어떻게 움직일지가 Action이 된다. 상대 말을 잡게 되면 보상이 주어지는데, 상대 말이 멀리 떨어져 이동할 때 까지의 시간이 필요할 수 있으므로, 상대 말을 잡는 보상은 당장 주어지지 않는 경우도 생길 수 있다 (지연된 보상). 따라서 강화학습에서는 당장의 보상값이 조금은 적더라도, 나중에 얻을 값을 포함한 보상값의 총 합이 최대화되도록 Action을 선택해야 하며, 게다가 행동하는 플레이어는 어떤 행동을 해야 저 보상값의 합이 최대화되는지 모르기 때문에, 미래를 고려하면서 가장 좋은 선택이 뭔지 Action을 여러 방식으로 수행하며 고민해야 한다. 좋은 선택이 뭔지 Action을 찾는 것을 탐색, 지금까지 나온 지식을 기반으로 가장 좋은 Action을 찾아 그것을 수행하는 것을 활용한다고 하여, 강화학습을 푸는 알고리즘은 이 둘 사이의 균형을 어떻게 잡아야 할지에 초점을 맞춘다. 위 방법들과는 다르게 실시간으로 학습을 진행하는게 일반적이다.
4 알고리즘
기계학습의 개략적인 알고리즘에 대해 기술한다. 이것에 대해 자세히 공부하고 싶으면 컴퓨터학과에 진학하는 것을 추천한다.
4.1 확률 기반
확률 기반 기계학습 알고리즘은 대부분 베이즈 정리에 기반한다. 베이즈 정리는 다음과 같은 형태로 확률적 추론에 이용되는 정리이다.
[math]{P(Y|X) = \frac{P(X|Y)P(Y)}{P(X)}}[/math]
여기서 P(Y|X)는 조건부 확률로 "X가 주어졌을 때 Y가 발생할 확률"로 생각하면 된다.
의학 진단의 예를 들어 수식을 설명하자면 X가 "열이 많이 난다"고 Y가 "독감"이라면, P(Y|X)는 열이 많이 나는 환자가 독감 환자일 확률, P(X|Y)는 독감 환자가 열이 많이 나는 확률, P(X)는 환자 중에 열이 많이 나는 환자가 있을 확률, P(Y)는 환자 중에 독감이 발생한 환자가 있을 확률이다.
여기서 베이즈 정리의 강력함은 "열이 많이 나는 환자가 독감 환자일 확률"(구하기 힘든 값)을 "독감 환자가 열이 많이 날 확률"(구하기 쉬운 값)로 추정할 수 있다는데 있다.
아래는 베이즈 정리에 기반한 대표적인 알고리즘들이다.
4.1.1 Naive Bayes Classifier (NBC)
이름에서 알 수 있듯이 베이즈 정리를 활용한 가장 단순한(naive) 분류기이다.
[math]Y[/math] 가 일어날 원인 [math]{X_1, X_2, X_3, ..., X_N}[/math] 이 서로 독립임을 가정하면 [math]{P(X|Y) = \Pi_{i=1}^N P(X_i|Y)}[/math] 임을 이용하여 [math]{P(Y|X) = \frac{P(X|Y)P(Y)}{P(X)} \simeq \frac{\Pi_{i=1}^N P(X_i|Y)P(Y)}{P(X)}}[/math] 으로 레이블을 추정하는 알고리즘이다.
여기서 각 확률값의 연산과 증명은 대학교 미적분 때 배우는 lagrange multiplier를 통해 진행할 수 있다.
4.1.2 Hidden Markov Model (HMM)
은닉 마르코프 모델(HMM: Hidden Markov Model)은 마르코프 모델의 일종으로, 시계열 분석을 할때 자주 쓰이는 확률형 모델이다. 마르코프 모델이란 보통 여러개의 상태가 존재하고 상태간의 전이 확률을 마르코프 확률(Markov Property)로 정의한 것을 말하는데, 이때 상태=출력(관측값이 상태와 같음) 이면 마르코프 연쇄(MC: Markov Chain), 상태!=출력(관측값이 상태가 아님) 은닉되어있으면(함수라던가, 확률분포라던가..) HMM으로 부른다.
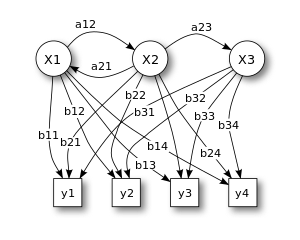 |
간단한 마르코프 모델을 잘 나타낸 그림으로, 상태 [math]X1[/math], [math]X2[/math], [math]X3[/math]가 존재하고, 상태가 전이할 확률 a12, a23,a21[1]이 존재한다. 다만 상태 X1,X2,X3는 직접적인 관측값을 나타내지 않으며 실질적인 관측값인 y1,y2,y3,y4가 일어날 확률을 X1에서는 b11,b12,b13,b14, X2에서는 b21,b22,b23,b24... 이런식으로 정의한다.
HMM의 주요 문제는 관측열이 나올수 있는 확률을 계산하는 평가(Evaluation), 관측열이 주어졌을때 이 관측열이 나올 확률이 가장 높은 상태열을 추측하는 해석(Decoding), 주어진 훈련셋트로 파라미터를 학습하는 훈련(Training)이 있다. 각 평가, 해석, 훈련 문제의 해결 방법은 Forward-backward 알고리즘, Viterbi 알고리즘, Baum-Welch 알고리즘이며, 이 셋모두 EM알고리즘에 속한다.
4.2 기하 기반
주어진 입력의 특징(feature)을 벡터(vector)로 만들어 특징 벡터끼리의 기하학적인 관계를 기반으로 추론을 진행하는 시스템을 이야기한다. 주로 벡터끼리의 거리나 코사인 유사도를 사용한다.
예를들어 가장 원시적인 형태의 검색엔진의 경우에는 문서에 어떤 단어가 몇 개 있는지를 벡터로 만든 후, 검색어도 마찬가지로 벡터로 만들어 벡터 유사도를 통해 문서를 순위화 하는 Vector Space Model을 사용하였다.
4.2.1 K-Means Clustering
주어진 입력을 군집화 하는 비교사 학습 방법이다. 총 K 개의 클러스터가 있다고 가정하고, 특징 공간(feature space)에서 K 개의 중간점(centroid)를 찾는 알고리즘이다.
4.2.2 k-Nearest Neighbors (k-NN)
지도학습 모델이다. 레이블 되어 있는 학습 데이터가 있을 때, 각 레이블마다 학습 데이터의 중간점을 구한다. 그 후 입력된 특징 벡터 X에 가장 가까운 중간점에 해당하는 레이블을 사용하는 분류기이다.
4.2.3 Support Vector Machine (SVM)
Support vector란 특징 공간에서 주어진 두 분류의 데이터를 구분지을 수 있는 최적(optimal)의 초평면(hyperplane)을 의미한다. SVM은 그러한 support vector를 찾는 알고리즘으로 두 분류에서 가장 가까운 데이터를 하나씩 찾아서 그 거리를 계산했을 때 가장 멀어질 수 있는 초평면을 찾는 것을 목표로 한다.
이것만 하면 단순한 linear classifier이어서 xor과 같이 직선으로 나눌 수 없는 함수는 학습을 진행하지 못하지만, SVM은 여기에 kernel function이란 개념을 도입하여 특징 공간을 접어버리거나 꼬아버려 선형으로 분류할 수 있게 만들어버린다.
기하 기반의 기계학습의 끝판왕으로 이것으로 필기인식, 사진 안에 있는 물체 인식, 영화 리뷰 분석 등 온갖 문제를 해결한다.
첨언 하자면 SVM의 기본원리는 함수해석학에서 배우는 3개의 정리 중, 한 바나흐 정리에서 찾아볼 수 있다. 이 정리의 기하학적인 버전이 어느 벡터 스페이스에서 두 개의 인터섹션이 비어있는 컨벡스한 섭셋이 정의 되었을 때 (점들을 이어서 두 개의 convex hull을 만들어도 된다), 두 컨벡스한 섭셋 A와 B를 나누는 초평면이 반드시 존재한다라고 하고, 이는 곧 SVM의 실현 가능성을 의미한다.
4.3 인공신경망
뉴런을 수학적으로 모델링한 후 시뮬레이션하여 인간의 뇌와 같은 학습 능력을 갖게하고자 하는 알고리즘이다. 주로 패턴인식에 많이 쓰이는데, 다른 알고리즘들보다 향상된 성능을 가지고 있다.
단점으로는 두가지가 있다. 첫째로 복잡한 연산일수록, 더 높은 정확도를 얻고 싶을수록 학습 데이터를 아주 많이 필요로 한다.[2] 둘째로, 연산량이 많다. 엄청난 양의 단순계산을 수행해야 하기 때문에 학습하는 데 시간이 오래 걸린다. CPU보다 GPGPU로 연산하게 되면 훨씬 더 빠르게 계산할 수 있다. [3]
뉴런 항목을 보면 알 수 있듯이 뉴런은 수상돌기에서 주변에 있는 다른 뉴런들로부터 오는 신호를 수용한 뒤, 신호의 강도가 특정 역치값을 넘어가면 축삭돌기를 통해 다른 뉴런에 신호를 보내는 세포이다. 이를 수학적으로 모델링 하면 다른 뉴런에서 들어오는 신호 벡터 [math]x[/math] 에 신호를 수용하는 수용체의 민감도(가중치) 벡터 [math]w[/math] 를 곱한 후, 역치값 [math]b[/math] 과 비교하는 형태의 모델이 나오게 된다.
따라서 인공 뉴런의 출력은 [math]wx + b[/math] 의 값이 되게 되는데 이 식을 그대로 사용할 경우 출력값이 [math]x[/math] 에 따라 실수 전체 범위에서 선형적인 값을 갖는 linear model이라 하고, 분석능력이 상당히 떨어지는 원시적인 모델이 되어버린다. 이를 해결하기 위해 non-linear model이 나왔는데 실제 뉴런의 행동 방식처럼 역치부분에서 값이 극적으로 변하는 함수를 사용한다. 대표적으로 sigmoid 함수를 사용하는 logistic model이 있고, tanh나 softmax 함수를 사용하는 다른 여러 모델들이 있으며 이 때 사용되는 함수를 활성화함수(activation function)라 한다.
4.3.1 Perceptron
Perceptron은 위에서 설명한 뉴런의 수학적 모델을 일컫는 용어이다. 이 알고리즘은 이름 그대로 하나의 뉴런을 사용하며 학습 데이터를 가장 잘 설명할 수 있는 최적의 패러미터( [math]w, b[/math] )값을 찾는다.
학습은 학습 데이터를 넣은 후 결과가 원하던 결과보다 크면 결과가 작아지게 패러미터를 조정하고 원하던 결과보다 작으면 커지게 패러미터를 조정하는것을 반복한다. 이것으로 학습이 가능하다는 것은 perceptron convergence theorem이란 이름으로 증명이 되어 있다.
4.3.2 Multi Layer Perceptron (MLP)
말그대로 여러개의 Perceptron 층(Layer)들을 중첩시켜 만든 모델을 뜻한다.
여러개의 Perceptron이 하나의 층(Layer)을 구성하며, 일반적으로 3~6개 정도의 층을 두며, 이들을 각각 입력층(Input layer), 은닉층(Hidden layer), 출력층(Output layer) 으로 구분하여 부른다. 필요이상으로 많은 층을 두는 것은 오히려 성능이 떨어진다고 알려져있다. 처음에는 중간에 존재하는 은닉층을 학습시킬 방법이 없기에 사장되었지만, 해결할 방법을 꾸준히 연구한 결과 80년대에 backpropagation이라는 알고리즘이 발명되어 사용할수 있게되었다. 신경망계통 알고리즘답게 초창기에 반짝하며 신드롬을 일으킬정도로 관심을 받았지만 당시 연산능력의 한계로 금세 사장되고 만다. 그리고 10년이 지난 2000년대 후반...
4.3.3 Deep Learning
MLP, 가치망, 정책망 등 다양한 종류의 인공신경망을 "복합적으로", "아주 깊게 (deep) 쌓는"것을 가리킨다. 정확한 정의가 있다고 보기보단 Buzzword (유행성 단어) 에 가깝다 뭔가 멋있잖아.
인공신경망 자체는 꽤 오랫동안 존재해 왔고, CNN이나 RNN과 같은 신경망 모델도 80년대에 활발히 연구되었던 주제다. 하지만 당시 컴퓨터로는 사실상 쓸만한 모델구현이 불가능 했고, 십수년동안 이론적인 방법으로만 여겨졌다. 그리고 2000년대에 들어서야, 그 이론들이 현실로 다가온 것! 물론 20년동안 컴퓨터만 발달했던 것은 아니다. 하지만 한동안 학계에서 "인공신경망"이란 단어가 논문에 들어가면 퇴짜맞는다는 소문이 있었을 정도로 학계가 무관심을 넘어서 혐오 했었고, 소수의 소신있는 연구자들만 인공신경망 연구를 진행해 왔었다.
2009년대부터 엄청난 신드롬을 일으키며 인공지능 분야의 구세주로 추앙받고있다. 단적인 예로, 페이스북의 딥러닝 기반 얼굴인식 모델인 deepface는 인식률 97%를 돌파하며 인간과 거의 성능차이가 없을 정도이며, 물체인식 대회에서 딥러닝의 일종인 CNN(Convolution Neural Network)는 그간 이어져오던 물체 인식알고리즘을 모두 순위권 밖으로 몰아내며(...) 랭킹 줄세우기를 하였으며, 음성인식 분야에서는 아무것도 모르고 그냥 가져다 박기만 했는데 인식률이 20%가 넘게 향상되었다는 소문이 들리고 있으며, 구글은 아예 이를 이용하여 게임하는 방법을 스스로 학습하는 인공지능을 만들거나 검색결과를 이용해 고양이의 개념과 생김새를 학습하는 머신을 만들어낼정도이다. 네이버와 다음과같은 국내 기업도 딥러닝을 적극적으로 연구중에 있다고 한다.
딥러닝의 가장 큰 특징은 무식하게 모델의 부피를 키우고, 데이터를 쏟아부으면 그만큼의 성능이 향상된다는 점이다..[4] 실례로 네이버의 Deview2013에서 딥러닝에 대한 세션이 있었는데 딥러닝 이전과 이후를 각각 청동기 시대와 철기 시대에 비유할정도로 딥러닝을 높게 평가했다.
다만, 어떤 사람들은 딥러닝을 다른 기계학습과 동떨어진, 마법의 기술처럼 착각하는 경향이 있는데, 사실 많은 기계학습 알고리즘이 딥러닝의 한 종류라고 볼 수 있다. 예를 들어 딥러닝 이전에 가장 유행했던 SVM도 결국 activation 없는 (linear) single layer perceptron에다 hinge loss function + Frobenius norm regularization 을 사용한 것이다. Logistic regression 은 말할 것도 없고,..
4.4 기타
5 예시
구글에서 인공신경망을 사용하여 이미지를 보고 이미지를 설명하는 캡션을 작성하는 인공지능을 만들었다고 한다. [1]
실제의 많은 기계학습 연구에는 고가의 그래픽 카드가 쓰인다. 그래픽 카드의 병렬처리가 기계학습에 알맞은 까닭이다. 마이크로소프트는 그래픽 카드 이상의 성능을 내기 위해서 FPGA를 연구하고 있다. 바이두는 FPGA 회사인 알테라와 협력하여 딥 러닝을 연구중이다. 엔비디아는 기계학습에 많은 투자를 하고 있으며 기계학습 연구 툴 DIGITS을 개발하였다.
그래픽 카드의 병렬 처리에 대한 컴퓨터 아키텍처 관련 정보는 GPGPU 를 참고하면 된다. 요즘 매체에서 많이 보이는 딥러닝용 슈퍼컴퓨터의 내부는 이것이 탑재되어 미친 듯이 전기를 흡입한다.
6 대학에서의 기계학습
컴퓨터공학과에서 다루고 있다. 컴공 안에서도 기계학습 석사 같은 별도의 과정도 생겨나고 있다. 학부과정에서 공부하려면 한계가 있으며, 제대로 기계학습을 공부하려면 관련 연구실을 찾아서 최소 석사, 가능하다면 박사 과정을 이수하는 것이 좋다.
2016년 미래창조과학부에서 미래 성장동력으로 선정되면서 앞으로 중요도와 대학내 입지가 커질것으로 기대된다.기사링크이미 아는사람은 다 알정도로 퍼졌지만
7 취업에서의 기계학습
- 재무적 리스크를 분석하는 직무에서 기계학습 전공자를 우대한다.
- 검색엔진을 다루는 IT 기업들.
8 관련항목
- ↑ 여기서는 일부 상태로의 전이확률이 나타나지 않았지만, 보통 전이 확률은 자기자신을 포함한 모든 상태로의 확률분포로 나타낸다.
- ↑ 정확한 규칙은 없다. 많이 넣을수록 좋은 결과가 나오기 때문이다. 최소치는 자유도에 10배를 곱해주는 것이라 하는 사람이 있다. 예를 들어 weight 3개짜리 연산의 경우 데이터 30개로도 가능할 수 있다. 하지만 32×32 그림 파일은 3072개의 특징을 가지고 있기 때문에 5만개 이상의 데이터를 필요로 한다.
- ↑ 2010년대 중반의 경우 GPGPU가 CPU보다 성능에 따라 10배쯤 빠를 수도 있다.
- ↑ 다만, 거대한 딥러닝 모델을 만들고 최적화하는 것은 절대 쉬운일이 아니므로 쉽게 생각해서는 안된다. 또한 데이터를 쏟아 부을 수 있을정도로 확보하는 것도 절대 쉬운 것이 아니다. 그리고 이 많은 데이터를 그 큰 모델에 넣으려면 그만큼 많은 연산서버가 필요하다. 즉 돈이 필요하다.