 |
Heterogeneous System Architecture
이기종 시스템 아키텍처
1 개요
파일:WEvYSAn.png
HSA(Heterogeneous System Architecture)란 이기종 시스템 아키텍처의 줄임말이다.
{kind=link}
동일한 성격의 코어를 모은 프로세서(멀티코어 CPU나 GPU) 를 가리켜 호모지니어스(Homogeneous)라고 하고, 이와는 반대로 전혀 다른 역할을 하는 코어를 하나로 통합한 프로세서를 가리켜 헤테로지니어스(Heterogeneous)라고 부른다.
여기서 호모지니어스 통합이 멀티코어 프로세서이고, 헤테로지니어스 통합이 HSA다.
HSA는 헤테로지니어스인 CPU와 GPU를 하나의 연산체로 간주하는 추상 계층을 생성해 GPU를 연산 보조용으로 사용하고, CPU와 GPU 사이에 데이터가 오갈 필요를 없앤다는 것이다. 즉 HSA란 CPU와 GPU를 하나의 칩으로 통합시키고 둘 사이에 긴밀한 연계를 추구하는 것이다.
이는 GPU가 발전하면서 이를 새로운 연산 장치로 활용하려는 시도가 있었고, 이로부터 도출된 문제점과 그 해결책을 찾아가면서 만들어지게 된 개념이다. 간단하게 GPGPU를 지금보다 더 활용하기 쉽도록 하다는 아키텍처 설계법이라고 보면 된다.
AMD APU에서는 외장 그래픽카드를 사용해도 iGPU를 HSA로 사용해 CPU의 연산 속도에서 비약적인 향상을 가져온다.
2 HSA 재단

2012년, AMD가 이기종 시스템 아키텍처 연구를 하기 위해서 만들어진 설립한 비영리 재단이다.
ARM 진영을 비롯하여, 모바일 칩셋을 생산하는 회사들이 대거 가입해 있다(삼성전자도 여기에 속해 있다). 이처럼 HSA기술은 ARM 진영에서 환영 받고 있다.
인텔, NVIDIA, IBM을 비롯하여 독자 플렛폼으로 GPGPU 분야에 진출중인 회사들은 가입되어 있지 않다. 더구나 이 세 업체가 차지하는 반도체 칩셋 비중이 전체의 3분의 1이다.
게다가 인텔은 스카이레이크에서 HSA 재단에 가입하지도 않고 HSA를 지원하기 시작했다. OpenCL 2.0에서 HSA 가 표준 명령어로 포함되었기 때문에 OpenCL을 지원하는 소프트웨어에서는 HSA를 활용할수 있게 된 점이 AMD 입장에서는 오히려 독이 될 수도 있는 상황.[1] NVIDIA도 아직까진 떡밥 수준에 불과하지만, 그래픽카드에 ARM CPU를 내장해 버리는 계획이 실현될 경우 이를 위해 HSA 지원을 할 가능성이 있다.[2] 다만 설령 저 시나리오가 실제로 일어난다고 해도 CUDA를 확장하거나 OpenCL 2.0(또는 그 이후 버전)를 통해 지원하는 등, HSA 재단과는 따로 놀 가능성도 있기 때문에 속단은 금물.
자세한 내용은 HSA 재단(영문) 참고.
3 역사
개념 자체는 예전부터[3] 제시되었지만, HSA라는 이름을 가지게 된 역사는 짧다. HSA라는 이름이 나오게 된 것은 2000년대 중반 경이었고, HSA 재단이 설립된 건 불과 2012년경이다. (사실 HSA는 기술명이고, AMD가 밀었던 브랜드는 Fusion이다. 하지만 Future is Fusion 마케팅을 밀던걸 너 고소 먹고 브랜드를 바꿀뻔 하다 보니 HSA란 이름이 전면으로 나오게 된 것. [4][5] 그리고 HSA를 지원하는 AMD의 첫번째 하드웨어는 카베리로서, 2014년 1월에 발매되었다.
또한 OpenCL 2.0에서 HSA 가 표준 명령어로 포함되었기 때문에 OpenCL을 지원하는 소프트웨어에서는 HSA를 활용할수 있을 예정이다.
하지만 가야할 길이 아직 멀다.
4 HSA의 개념
{kind=link}
4.1 hUMA

hUMA(heterogeneous Uniform Memory Access)
서로 다른 프로세서(CPU와 GPU)의 메모리 영역을 통일하여 메모리 영역을 공유한다는 개념이다. 한마디로 GPU가 CPU와 같은 수준으로 취급되며, 동일한 메모리에 액세스할 수 있다는 것이다.
기존 방식은 CPU와 GPU가 서로 다른 메모리 영역으로 나뉘어져 있다.[6][7] 이렇게 따로 떨어진 메모리 사이에서는 데이터 처리시 동기화와 주소 변환이 필요하다. 이를 CPU와 GPU가 공유하는 추상화된 메모리 계층을 생성해 동일한 메모리 어드레스를 사용하여 해결한다는 것이다.
이 과정에서의 CPU와 GPU의 양방향 메모리의 일관성을 하드웨어로 유지하게 된다. 양방향으로 하드웨어가 캐시를 스누프하고 일관성을 자동으로 확보한다. 어느 프로세서가 캐시의 데이터를 갱신했을 경우 다른 프로세서를 탐지할 수 있어 메모리 일관성의 에러가 생기지 않도록 하는 것이다.[8]
기존의 데이터 연결방식은 "CPU - 주 메모리 - GPU 메모리 - GPU" 였는데 주 메모리와 GPU 메모리 영역을 통합시켜 "CPU - 공유 메모리 - GPU" 로 연결한다는 것이다.
직렬(연속적인) 작업 담당하는 CPU와 병렬화 작업를 담당하는 GPU를 효율적으로 묶는 게 hUMA의 역할이다. 이를 통해서 GPU에서 실행하는 범용 프로그램을 지금보다 더 간단하게 쓸 수 있도록 하는 것이다.
- 장점: 간단해진 작업 스케줄로 관리가 편해진다.
- 데이터 처리 단계가 줄어들어 작업 스케쥴이 단순해지며 지금까지는 CPU와 GPU 간 데이터 전달을 OS가 관리하였기 때문에 데이터 추적이 힘들었는데, 복사할 필요가 없어짐으로써 데이터 추적이 간단해지고 메모리 관리가 훨씬 편해지게 된다.
- 이로 인해 줄어든 작업 스케줄만큼 더 빠른 처리가 가능해지고 또한 불필요한 메모리 액세스가 줄어들어 전력 소비도 억제할 수 있다.
- 또한 프로그래머 입장에서는 하드웨어간의 데이터 전달시의 데이터 간의 동기화 와 일관성 문제를 신경 쓸 필요가 없게 된다.[9]
- 단점: 시대를 역행한 기술이었다
- GPU전용 메모리인 GDDR은 일반 DRAM보다 월등히 빠른 속도로 동작한다.[10] 그런데 주메모리에 GPU 메모리 영역을 통합시킨다면 GPU의 동작 속도도 덩달아 떨어지게 된다. 이 점은 이 기술이 내장 그래픽 전용 기술이 될 수 밖에 없게 된 이유이다.[11][12] 인텔의 브로드웰에서는 L4 캐시로 128MB의 eDRAM을 넣는 방식으로 AMD APU를 뛰어넘는 성능이 나올 수 있었다.
- 게다가 지금까지의 만들어진 프로그램은 GPU 메모리로 데이터를 보내도록 만들어졌다.[13] 당연히 기존 프로그램과는 전혀 호환이 되지 않는다. 이러한 HSA의 장점을 살리기 위해서는 기존방식과는 다른 방식으로 데이터를 전송하도록 프로그램을 짜야 한다. 즉 기존 프로그램 사용자에게는 전혀 쓸모 없는 기술인 셈이다.
이외의 더 자세한 내용은 추가바람
4.2 hQ
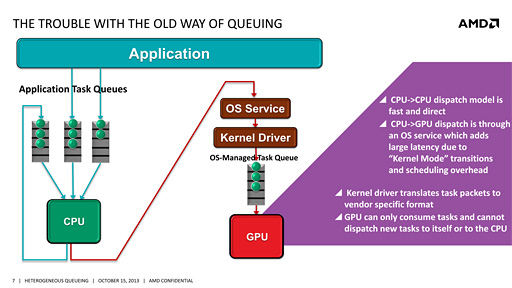
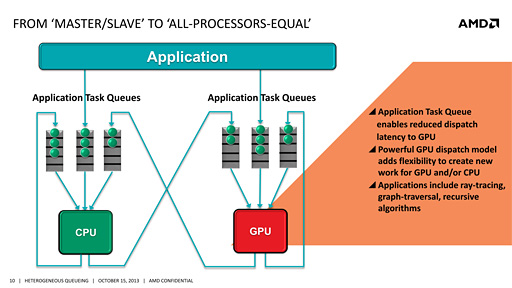
위가 기존 방식, 아래가 hQ(Heterogeneous Queuing)
hQ란 간단히 CPU와 GPU 사이에 있던 높은 장벽을 줄이는 방식의 구조를 말한다.
현재의 GPU처리는 OS에 의해서만 제어 될 수 있다. 그래서 GPU 접근은 애플리케이션 -> OS API -> 드라이버 -> GPU 의 방식으로 접근하는데 GPU가 작업을 실행할 때마다 이 과정을 거치게 됨으로써 GPU를 효율적으로 사용할 수가 없을 뿐더러, 이 과정에서 상당한 지연이 발생한다.[14]
그래서 사용자가 직접 GPU에 프로세스나 작업을 할당할수 있도록 한다는것이 hQ의 개념이고, 이를 위해 사용자가 GPU 작업을 실행하기 위한 구조를 하드웨어 단계에서 제공하는 것이 hQ이다.
- 장점: GPU 작업을 유저가 직접 액세스할 수 있다. 이에 따라서 기존 방식의 복잡한 계층 변환에 의한 접근이 필요하지 않게 되면서 오버헤드를 크게 낮출 수 있다.
CPU : 일이 줄었다! 야 신난다
- OS를 거치지 않기 때문에 GPU 작업을 실행하기 위한 패킷 형식을 HSA 기반 플랫폼 하에서 표준화할 수 있다. 즉 x86 기반 프로세서나 ARM 기반 프로세서도 HSA를 지원하기만 한다면 같은 포맷을 활용하여 GPU를 사용할 수 있게 된다.
- 단점: 잠재적인 호환성 문제가 생길수 있다.
- OS가 모든 주변기기를 제어하는 것은 그것이 사용자에게 가장 편리하기 때문이다. 사용자 애플리케이션이 하드웨어에 마음대로 접속할 수 있는 환경에서는, 애플리케이션의 호환성을 보증하지 못하고 보안도 지킬 수 없다.[15]
- 또한 hUMA와 비슷한 문제가 있는데 이 새로운 접근방식은 어플리케이션의 접근 방식도 완전히 바꾸어야 한다. 이 방식이 기존 방식보다 더 쉽고 빠르더라도 지금까지 쌓아올린 노하우를 전부 포기하고 새로운 하드웨어에 맞춘 새로운 방식의 프로그래밍 기법을 활용할 할만큼 모험심 강한 프로그래머도 많지 않다는 점이다.
- 게다가 이 새로운 하드웨어를 만들고 있는 회사는 시장 점유율이 20%에 불과하고 전체 하드웨어에서는 10% 안되는 규모인데 이러한 새로운 하드웨어에 맞추어 프로그램을 만들 회사도 많지 않다는 점이다.
마이너의 비애[16]
이 이상의 내용은 추가바람
5 HSA의 목표와 한계
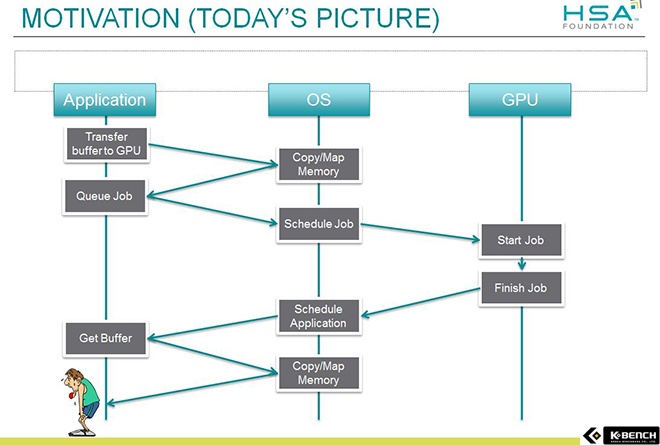 | 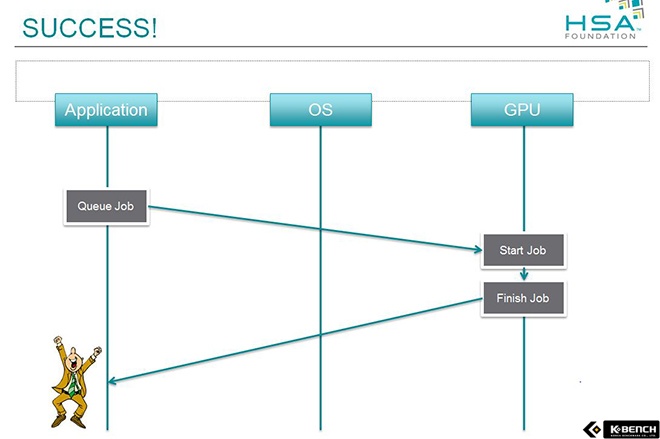 |
| 현재의 GPU 활용 방식 OS의 간섭이 많고 단계가 복잡하여 활용하기가 힘들다. | HSA의 GPU 활용방식 어플리케이션이 직접 GPU를 활용 할수 있도록 하여 효율을 높인다. |
HSA의 궁극적인 목적은 병렬 연산 프로그래밍의 확대이다. 이를 위해 GPGPU 프로그래밍의 난이도를 낮추고 하드웨어의 제약에 얽매이지 않게 동작할 수 있는 병렬 컴퓨팅 환경을 만드는 것이다. [17] 이 목적은 AMD가 2000년 중반에 내세웠던 해테로지니어스 코어라는 목표를 전 플렛폼으로 확대한 모습이기도 하다.
궁극적인 단계에서는사용자 입장에서 GPU는 CPU의 보조 연산 코어정도로 인식할 정도로 GPGPU 프로그래밍의 난이도를 낮추는것이 목표이다.
그러나 목적만큼 그 한계 역시 뚜렷하다. GPGPU 분야에서 선두주자인 NVIDIA의 CUDA를 끌어들이지 못했다는 점[18], 그리고 CPU쪽에서도 인텔을 끌어들이지 못해서 당장 대부분의 프로그래머들이 HSA에 대해서 영 좋지 못한 시선이다. 아무리 GPGPU 난이도가 낮아진다고해도 이를 이용할 하드웨어가 없다면 무용지물이다. 그런데 AMD는 카베리부터 비로소 HSA를 지원할정도로 늦은 속도로 HSA를 지원하는 하드웨어를 발표하고 있다.
게다가 인텔과 IBM도 독자 플렛폼으로 GPGPU 시장에 진출 중이라는 점은 장기적으로 HSA 프로젝트의 발목을 잡을 것으로 보인다.
단, 인텔도 HSA 지원에 대한 투자를 꾸준히 하고 있는데, 인텔이 GPGPU용으로 밀고 있는 독자 플랫폼인 제온 파이는 슈퍼컴퓨터등 HPC용이지 데스크탑이나 노트북에 쓸 수 없기 때문이다. (애초에 제온 파이 0세대, 흑역사 라라비를 출시 못 한 이유중 하나가 양쪽 다 간보다가 방향전환하다가 시기를 놓쳐서...) 스카이레이크부터는 공유 메모리와 OpenCL 2.0도 지원하는 등 HSA 지원이 가능한 하드웨어 구조를 가지고 있다. 더구나 캐시 구조를 생각하면 AMD보다도 앞서는 모습을 보인다. [19]
6 HSA 지원 프로그램
자세한 내용은 추가바람- ↑ 단, OpenCL 2.0을 통한 HSA 사용은, 정식 지원이라기 보다는, 꼼수에 가깝고 제약도 심하다고 한다.
- ↑ 다름 아닌 ARM이 HSA 재단의 설립 멤버기 때문.
- ↑ AMD 기준에서 ATI 인수 당시부터 계획하고 있었다.
- ↑ 링크한 파코즈 게시판 검색 결과의 경우, 09년도~12년도 초까지 'Fusion APU'라는 표현이 많이 사용되는데 12년도 중반부터 쏙 사라진다. 반면 같은 게시판에서 HSA 기사는 12년도 말부터 나온다.
- ↑ 여튼 13년 1월에 합의하긴 했다.
- ↑ NUMA라고 부른다.
- ↑ '서로 다른 메모리 영역으로 나눠진거 = NUMA' 가 아니다. 하나의 메모리 영역으로 되어 있어도 어떤 CPU core 에서 어떤 주소를 접근하느냐에 따라 latency / bandwidth 에서 성능차이가 나는 경우에도 NUMA 가 된다. 따라서 시스템 ddr 메모리와 그래픽카드의 외장 gddr 메모리의 메모리 영역이 하나로 합쳐지라도 ddr 과 gddr 메모리가 물리적으로 하나의 메모리로 통합되지 않는 이상에는, CPU 에서 ddr 메모리에 접근하는거랑 그래픽카드의 gddr 메모리를 PCIe 버스를 통해서 접근하는거랑은 latency / bandwidth 에서 성능차이가 날 수 밖에 없기 때문에 여전히 NUMA 로 남게 된다.
- ↑ 아주 아주 아주 간단하게 말해서 CUDA와 비슷한 방향으로 가고 있다고 생각하면 된다.
- ↑ 즉 과거 방식에서는 주 메모리와 GPU 메모리 간의 두 데이터의 일치 여부를 누군가가 확인해주어야 한다. 게다가 최적화를 위해서는 GPU메모리가 어느 정도까지 데이터를 한 번에 처리할 수 있는지 여부를 직접 프로그래머가 확인하고 여기에 맞추어 처리 할 데이터양을 조절해야 했다. 그런데 HSA에서는 그런 거 없다.
- ↑ 마치 RAID처럼 뱅크 그룹을 만들어 비약적인 속도 향상을 가져왔다. 하지만 GDDR이 일반 DRAM을 대체할 수 있다는 것은 아니다. 어디까지나 그래픽 연산에 한정된 성능이다. 그런데 HBM은 APU나 서버용 CPU에 넣는다는 소가 들리는 것으로 보아 정말로 DRAM을 대체할 지도 모른다 지도 모른다
- ↑ 물론 PS4처럼 주메모리로 GDDR5를 무식하게 때려 박는다면 아주 간단하게 해결되겠지만 콘솔이 아닌 일반 PC에서 DRAM을 GDDR로 대체한다는 것은 불가능하다.
- ↑ 정확하게 말해서 HSA는 외장 GPU 메모리와의 통합도 추진하고 있어 엄밀히는 틀린 말이다. 그러나 현실적인 한계로 아직은 내장그래픽에서만 HSA가 적용되고 있다.
- ↑ 주 메모리의 속도가 GPU 처리속도를 못따라오다보니 미리 처리할 데이터를 GPU메모리에 보내준다. 이를 '프리로딩' 이라고 하는데 자세한 내용은 해당 항목 참고.
- ↑ 물론 OS가 수행하는 모든 작업은 CPU가 담당한다. 즉 GPU를 활용하기 위해서 GPU에 접근할때 때마다 CPU는 엄청난 작업을 처리하는 셈이다.
- ↑ 간단하게 말해서 어플리케이션이 접근 해서는 안되는 위치의 메모리 주소에 접근하면 시스템이 다운되어 버린다. 이를 방지 하기 위해서 OS가 모든 하드웨어와 메모리 접근을 관리하고 있다. 그럼에도 접근할수 없는 위치에 어플리케이션이 접근한다면 OS는 블루스크린 등의 커널 패닉을 일으킨다. 즉 OS를 배제한 접근 방식은 잠재적으로 커널 불안정을 초래할 가능성을 내포하고 있다.
- ↑ 다만 ARM도 참여하니 속단은 금물.
- ↑ 예를 들어 AMD GPU/APU에서 동작하는 병렬 컴퓨팅 프로그램을 만들었다면 이것이 'ARM + POWER VR'에서도 프로그램 수정없이 돌아갈수 있다는 것이다.
- ↑ CUDA는 대표적인 폐쇄 플랫폼이다. NVIDIA GPU에서만 돌아가는 녀석이니...
- ↑ AMD는 카리조까지도 CPU와 GPU가 공유하는 캐시 메모리가 없다. 그래서 해당 기능이 필요한 AMD 후원 HSA 성능 연구는 HSA와 L3 캐시를 모두 가진 가상의 APU를 시뮬레이션 해서 쓰기도 한다. (연구 당시 인텔은 HSA를 지원하지 않았다.)