- 상위 항목 : ARM(CPU)
1 종류

위의 그림과 같이 2015년경을 기점으로 고성능-고효율-초고효율 이라는 3단계 라인업으로 구성이 정리된 상황이다[1]. 이는 일반적으로 언급되는 하이엔드-메인스트림-엔트리 개념으로 봐도 무방하다.
Cortex-A 시리즈에 적용된 명령어셋은 ARMv7-A 부터이며, 이전 세대의 ARMv6 명령어셋 아키텍처는 ARM11 계열까지 적용되었다.
2013년에 ARMv7-A의 후속 명령어셋인 ARMv8-A이 공개되었으며 가장 큰 특징은ARMv8-A 안에 AArch32와 AArch64라는 두 가지 서브 명령어셋이 도입되면서 AArch64를 통해 64비트 구조를 쓸 수 있게 된 점이다. 이후 대부분의 신형 Cortex-A 시리즈와 커스텀 아키텍처들은 ARMv8-A에 기반하여 활발하게 개발되고 있다.
1.1 ARMv7-A
1.1.1 Cortex-A5
{kind=link}
2009년 10월에 발표된 저사양 CPU 아키텍처다. Cortex-A5는 전성비 극대화를 추구하면서 기존의 ARM11과 유사하게 싱글 파이프라인 구조를 유지했다. 그래서 성능은 ARM11보다 약간 더 좋은 정도로, ARMv7-A 명령어 셋을 지원하는 CPU 아키텍처 중에서 가장 성능이 낮지만 전력 소모율도 매우 낮다. 그래서 ARM에서는 아직도 흐르고 넘치는 100개 이상의 ARM9 내지는 ARM11 아키텍처 라이센스 취득사가 Cortex-A5를 대체재로 이용할 수 있도록 독려하고 있다.
또한 Cortex-A9처럼 멀티코어화가 가능하다. 때문에 임베디드 시스템 뿐만이 아니라 저사양 스마트폰에도 종종 탑재되고 있으며 퀄컴 역시 스냅드래곤 200에 Cortex-A5 멀티코어 CPU를 사용하는 라인업을 잡아두었다. 다만, 쿼드코어 구성이라 하더라도 성능은 옴니아 II에 들어간 ARM11을 네 개 붙여 놓은 것과 비슷하기 때문에 많은 것을 기대하기는 어렵다.
1.1.1.1 사양

- 8단계 파이프라인
- 한 사이클에 1개의 명령어 디코더 (DE) - 64k
- NEON/vfp SIMD 유닛을 외장 형태로 부착 가능
- Issue 명령 분배기 1개가 모듈 2-3개로 분배
기본적인 연산 모듈은 2개이다.
- A-ALU
- B-Load/Store -AGU
- C - Neon/vfp - 외장형 옵션
ARMv7-A 기반 아키텍처 중에서 유일하게 1개의 디코더를 가지고 있다. L2 캐시는 지원하지 않으며 Neon/vfp도 필요에 따라서 외장으로 따로 부착하는 형태이다. 다만 ARMv7-A 자체의 성능이 준수하기 때문에 아무리 저사양이라고 불리는 Cortex-A5의 성능은 ARM11의 120%정도.
1.1.2 Cortex-A7
{kind=link}
2011년 하반기에 발표된 엔트리급 CPU 마이크로 아키텍처다.
전체적으로 Cortex-A5의 연장선상에서 개발된 아키텍처다. Cortex-A8이 주력이었던 시기에는 65nm, 45nm 공정이 주력 공정이었으나 Cortex-A7은 그보다 훨씬 미세한 공정에서 제조된다. 이러한 공정 미세화와 기술 진보로 인해 성능은 Cortex-A8과 비슷한 수준이지만 그 성능을 내기 위한 전력 소모는 5배 이상 적다. ARM의 목표대로 2010년에 $500 정도의 스마트폰 성능을 2013년에 $100 ~ 200 정도의 스마트폰 성능으로 만들어준 주역이다.
기본적으로 모든 유닛이 Cortex-A8과 같은 순차적 명령어 처리지만, Cortex-A9의 특징이었던 멀티코어 지원, NEON 및 L2 Cache 내장, ALU 모듈의 나눗셈 지원 등이 추가되었다.
간단한 구조와 전력 소모가 적은 설계를 기반으로 고성능 CPU 아키텍처의 자비 없는 전력 소모량을 보완하기 위한 big.LITTLE 솔루션에서 Cortex-A12와 Cortex-A15의 LITTLE 코어를 담당한다. 하지만 자체적인 성능 역시 나쁘지 않고 설계와 양산도 쉽기 때문에 Cortex-A7로 이루어진 모바일 AP도 퀄컴과 미디어텍 그리고 여러 중국산 업체를 중심으로 활성화되고 있다. 예로 Cortex-A7 기반 삼성 엑시노스 5410의 LITTLE 코어와 Cortex-A9 기반 NVIDIA Tegra 3의 성능이 비슷한 결과가 있기도 했었다.
1.1.2.1 사양
{kind=link}
- 8단계 파이프라인 + 슈퍼스칼라
- 한 사이클에 2개의 명령어 디코더(DE) - 128k
- 명령어 발행 어레이 개수 = 1
- Issue명령 분배기 1개가 5라인(in) 파견 5개
- L2 Cache 내장
연산 모듈은 총 5개(A~E)
- A - ALU(in)-정수연산 덧/뺄셈
- B - ALU(in)-정수연산 덧/뺄셈+곱/나눗셈
- C - NEONvfp
- D - Dual issue-Superscalar
- E - load/store
저전력을 목적으로 나온 코어답게 간단한 설계를 보여주고 있다. 기본적으로 모든 유닛은 순차적 명령어 처리 방식이지만, L2 Cache, NEON SIMD의 통합 등 진보적인 설계를 도입함에 따라 실제로는 Cortex-A8 이상의 성능을 보여주고 있다. Cortex-A7의 ALU는 Cortex-A12나 Cortex-A15의 ALU같이 나눗셈을 지원하며, 그 외의 다른 특징으로 Dual-Issue가 가능한 슈퍼스칼라 유닛을 추가하여 제한적으로 1사이클당 2개 명령어 처리가 가능하도록 되어 있고 기존 A8/A9와는 달리 파이프라인 구조 안으로 NEON 연산 유닛을 통합함으로써 연산 성능을 향상 시키고 있다.
1.1.3 Cortex-A8
{kind=link}
2005년 중반기에 발표된 첫 ARMv7-A 기반의 CPU 아키텍처이자 Cortex-A 시리즈의 첫 번째 제품이다.
이전 세대 ARMv6기반의 ARM11 아키텍처와 비교 했을 때 중요한 변경점은 2 Issue in-order 슈퍼스칼라 처리 구조가 도입된 것과, NEON SIMD가 기본으로 지원되면서 클럭 당 동시 명령어 처리 능력, 클럭 당 동시 데이터 처리 능력이 향상되어 정수 및 멀티미디어 데이터, 부동 소수점 연산 능력 모두가 향상되었다.
ARM이 Texas Instruments와 같이 설계했던 첫 Cortex-A8 기반 AP인 OMAP 34XX에서 최대 클럭을 800MHz까지 밖에 끌어올리지 못했기 때문에, 초기 최대 클럭은 800MHz였다. ARM에서는 800MHz가 한계라 보고 삼성전자를 만류했지만, 이후 삼성전자가 코어 커스텀을 통해서 1GHz를 돌파하고, ARM도 코어 리비전을 통해 1GHz로 끌어 올림에 따라 보편적인 최대 클럭은 1GHz가 되었다.
아키텍처가 발표된 당시에는 ARM에서 아키텍처를 발표하고 해당 아키텍처가 적용된 제품이 나올 때까지 3~4년 정도 걸렸다. 그래서 A8 코어를 적용한 제품들이 본격적으로 출시된 것은 2009-2010년이었고 옴니아 HD 같은 높은 프로세싱 능력이 필요하고 리소스 소모 역시 큰 제품에 먼저 사용되었다. 이후 애플이 아이폰 3GS에 삼성전자의 S5PC100 600MHz를 사용하면서 기존 ARM11을 사용한 옴니아 II를 눌러버렸다. 옴니아 II의 CPU 클럭은 당시에도 고클럭이었던 800MHz였지만, 체감 성능 차이는 운영체제를 차이를 감안해도 상당히 컸다.
이후 안드로이드 탑재 스마트폰들에 의해 스마트폰 시장이 급성장하기 시작하면서 Cortex-A8을 사용한 AP들이 덩달아서 활발히 출시되었고, 동 세대 비교 대상이었던 퀄컴 스냅드래곤 S1 및 S2의 Scorpion 아키텍처보다 클럭 대비 성능이 뛰어나다는 평가를 받는다.
1.1.3.1 사양
{kind=link}
- 한 사이클에 2개의 명령어 디코더
- Issue명령 분배기에서 3개의 연산모듈로 파견
3개의 연산 모듈
- A - ALU/MUL : 정수 연산 모듈, 덧/뺄셈 및 곱/나눗셈 지원
- B - ALU
- C - LS - 로드/스토어 모듈
1.1.4 Cortex-A9
{kind=link}
2007년 3월에 발표된 Cortex-A8의 후속작으로, 시기상으로 2년 미만의 차이밖에 없는 Cortex-A8에 비해 혁신적인 수준으로 구조가 개선되었다.
첫 번째로 멀티 코어를 기본적으로 지원하면서 최대 쿼드 코어까지 구성이 가능해지면서 모바일 분야에서도 멀티 코어를 손쉽게 구성할 수 있게 되었다. 두 번째는 비순차적 명령어 처리를 도입했다. 원래 비순차 명령어 처리 기능의 경우 전성비 측면에서 불리하여 모바일 분야를 타겟으로 한 제품으로의 도입에 부정적이었으나 결국 A9를 기점으로 도입이 성사되었다.
이 외에 L2 Cache의 도입같은 변화점이 있다.
Cortex-A8은 아키텍처 발표부터 시장 진입까지 5년 정도 걸렸지만, A9는 4년으로 짧아졌다. 2011년 1월에 공개된 NVIDIA Tegra 2가 Cortex-A9 탑재 첫 제품이었다.
더군다나 Cortex-A9의 멀티코어 구성으로 2010년부터 본격화된 안드로이드 스마트폰 열풍은 정점을 찍게 된다. 특히 삼성전자의 엑시노스 4210을 사용한 갤럭시 S II의 성공으로 더욱 가세되었기 때문이다. 이 뿐만이 아니라 Cortex-A8보다 진보한 아키텍처 구조로 클럭 당 성능비도 증가했으며 멀티 코어화로 인한 성능 상승폭은 거의 코어 수에 비례하기 때문에 단순이 코어 개선의 효과보다 큰 성능 향상이 있었다.
이러한 Cortex-A9 멀티 코어에 대응하기 위해 퀄컴은 Scorpion 아키텍처를 멀티 코어화 시키고 고클럭화를 목표로 파이프라인을 늘려 1.5GHz의 클럭을 달성하지만 태생적으로 클럭 대비 성능이 Cortex-A9보다 밀리기 때문에 성능은 성능대로 놓치고 발열은 발열대로 놓쳤다. 이후 Krait 아키텍처가 나오지 전까지 퀄컴 스냅드래곤의 이미지가 하락하게 된 원흉이 되었다.
1.1.4.1 사양
파일:Attachment/ARM Cortex-A 시리즈/cortex-a9.jpg
{kind=link}
- 8~11단계 파이프라인
- 한 사이클에 2개의 명령어 디코더 (DE) - 64k
- 명령어 발행 어레이 개수 = 1
- ISSUE명령 분배기 1개가 3+1라인(in) 한번에 파견은 최대 3개
- 외장 L2 Cache
연산 모듈은 총 4개
- A1 - ALU(out) : 정수 연산 모듈, 덧/뺄셈 지원
- A2 - ALU(out추가) : 정수 연산 모듈, 덧/뺄셈+곱셈 지원
- B - Load/Store - AGU
- C - NEONvfp (in)
Cortex-A8의 순차적 명령어 처리방법에서 진보한 비 순차적 명령어 처리를 지원한다. 다만 위의 파이프라인 개요도에서 볼 수 있듯이 파란색의 비 순차적 처리를 지원하는 모듈은 Issue명령어 분배기와 ALU 연산 유닛 뿐이다. 내장화 된 Neon 유닛과 AGU 자체는 순차적으로 명령어를 처리한다.
이전 Cortex-A과 ALU 유닛의 개수는 같지만 두 번째 ALU 유닛에서 정수 곱셈을 지원이 추가 되었다. 다만 이는 일종의 보조 유닛으로, Issue 분배기에서 한번에 보낼 수 있는 파견량은 3개로써 한번에 모든 연산 모듈에 명령을 보낼 수는 없다.
이를 만회하기 위해서 비교적 대용량의 L2 Cache를 코어에 외장으로 지원하며 운영체제에서 지원이 필요하다.
1.1.5 Cortex-A12
{kind=link}
2013년 6월 2일에 발표된 ARMv7-A 기반 아키텍처.
전반적으로 Cortex-A9와 Cortex-A15의 설계를 혼용하여 전성비를 높이는데 주력한 아키텍처이다.
A15/A7==>A57/A53이라는 주력 라인업과는 다르게 좀 갑툭튀한 느낌이 있는데, 사실 32비트 기반인 이 아키텍처가 제품화될 시기인 2015년에는 64비트 메인스트림인 A57/A53기반 제품들이 출시될 시기와 겹치게 될 상황이기 때문.
그런데 A12가 적용되는 타겟 공정은 2015년 시점에서는 저가 양산 라인으로 포지션하게 될 GF와 TSMC의 28nm가 될 예정이고, 반면 A57/A53기반의 하이엔드 제품들은 20/16/14nm공정 라인에서의 생산을 목표로 하고 있다. 2015년 시점에서 생산 단가가 떨어질 대로 떨어지게 될 28nm 공정을 활용하기에 기존에 개발된 A15는 해당 공정에서 전력 소모 특성이 좋다고 말하기 힘들어 사용이 제한되고, 그것보다도 복잡한 A57은 더더욱 28nm수준에서는 부적합하다고 추정할 수 있는 상황이다. 그럴 경우 28nm 공정에 적용할 만한 제품은 저성능의 A7/A9/A53로 한정되면서 중간급 라인업이 비어버리는 문제가 생긴다. 즉 원래는 시기적으로 A15가 미들 레인지로 내려오면서 채워 넣었어야 하는 부분을 A12가 대신 채워 넣어야 하는 상황이 된 것.
Cortex-A9와 비교했을 때 명령 디코더가 3개로 늘어났고, Cortex-A9가 정수 연산 부분에서 부분적으로 비 순차적 명령어 처리를 한 것에 반해서 Cortex-A12는 모든 연산 유닛이 비 순차적 처리를 지원한다. 또한 외장으로 Cortex-A53의 분기 예측기(Branch Predictor)를 도입하고 ALU 모듈에서 나눗셈을 지원, L2 Cache의 내장화 같은 개선점이 있다.
또한 미드레인지 라인업이지만, Cortex-A15와 같이 Cortex-A7 아키텍처와 조합해서 big.LITTLE을 지원한다고 한다.
전반적인 성능은 퀄컴 Krait와 애플의 Swift와 비슷할 것으로 예측되고 있다. 구조적으로는 Cortex-A15의 요소들을 최소한으로 잘라내어 Cortex-A9에 적용한 것으로 추측된다.
2014년 10월 1일 ARM 공식 홈페이지에서 Cortex-A12가 Cortex-A17로 통합되었다고 발표했다예토전생
1.1.5.1 사양
파일:Attachment/ARM Cortex-A 시리즈/cortex-a12.jpg
{kind=link}
- 10~12단계 파이프라인
- 한 사이클에 2개의 명령어 디코더(DE) - 128k
- 명령어 발행 어레이(Rename & Dispatch) = 2
- ISSUE명령 분배기 3개가[2] 각 2라인씩 총6라인 파견6개
- 내장 L2 Cache
연산 모듈은 총 6개
- A1- ALU(out) : 정수 연산 모듈, 덧/뺄/곱셈 + 나눗셈 지원
- A2- ALU(out) : 정수 연산 모듈, 덧/뺄/곱셈 + 나눗셈 지원
- B1- load/store(out) - AGU
- B2- load/store(out)
- C1-NEONvfp (out)
- C2-NEONvfp (out)
파란색이 비 순차적 명령어 처리 부분으로 ALU 모듈에서만 비 순차적으로 명령어를 처리했던 Cortex-A9에 비해서 모든 유닛에서 지원하게 되었다. 또한 Cortex-A15와 마찬가지로 명령어 발행 어레이와 Issue 분배기를 분리했다. 하나의 발행 어레이는 Neon/vfp SMID를 담당하며, 나머지 하나의 발행기가 ALU 모듈과 AGU 모듈을 통합해서 관리한다. 다만 Issue 분배기 자체는 3개로써 각각 2개의 연산 모듈을 담당하며 한번에 최대 6개의 명령어를 발행할 수 있다. 이는 Cortex-A9에서의 Issue 분배기가 한번에 최대 3개 까지 밖에 명령어를 발행하지 못했기 때문에 모든 연산 유닛을 활용할 수 없었던 것에 대한 개선점이다.
1.1.6 Cortex-A15
{kind=link}
2010년 9월에 발표된 Cortex-A9의 후속작이다. 발표 시기를 보면 Cortex-A7과 Cortex-A17보다도 빠르지만 성능은 ARMv7-A기반의 모든 아키텍처 중에서 가장 높다. 즉 위에서부터 읽었다면 했던말을 또 들을 수 있다. 사실, 이후에 발표된 Cortex-A17은 Cortex-A15의 성능을 유지하면서 전성비를 극대화한 아키텍처라 보면 된다.
전작인 Cortex-A9보다 향상된 ALU 유닛과 배수만을 따로 처리하는 ALU를 추가했고, 분기 예측기 연산 모듈을 내장했다. 또한 모든 유닛에 비 순차 처리 방식 도입을 하는 등 ARMv7-A 기반의 아키텍처가 보여줄 수 있는 최대한의 성능을 보여준다. 때문에 처리 능력에서는 코어 초기형 수준 x86 기반의 아키텍처들과도 견줄 수 있는 수준이다.
문제는, ARM이 추구하던 저전력 코어로서의 이점을 상당히 잃었다는 것인데...
내부 구조상 성능을 올릴 수 있는 모든 것을 때려 넣은 구조이기 때문에 이전의 ARM이 출시한 그 어떤 CPU 아키텍처보다 자비없는 발열과 이성을 잃은 전력 소모율을 보여준다. 때문에 크레이트 같은 모바일 지향으로 설계된 아키텍처에 비해 발열 문제를 처리하기 어려운 아키텍처가 되어버렸다. 32nm 공정에서는 듀얼 코어의 엑시노스 5250 정도가 태블릿 전용으로 탑재되었고, 2013년에 28nm 공정을 사용한 5410에 와서야 스마트폰에 탑재하는데 성공.어째 다 삼성이다? 다만 전력 소모는 경쟁 제품 대비 압도적인 모습을 보여주지는 못하고 있다.
다만 이러한 상황은 ARM 사가 A15의 포지션을 모바일뿐만 아니라 서버 영역까지 확장하면서 벌어진 것이며 ARM은 이 문제를 해결하기 위해서 모바일 영역에서는 big.LITTLE 방식을 도입하게 되었다. big.LITTLE은 서로 다른 종류의 CPU 코어를 한 시스템에서 제어해야 하고, 기존에는 잘 사용하지 않았던 새로운 형태의 멀티 프로세싱 모델이었다. 이 구조를 제대로 사용하려면 하드웨어 구성뿐만 아니라 운영 체제 커널에서도 작업을 효율적으로 분배해 주어야 했다. 커널 지원은 2013년 말경에 마무리 되었고 실제 출시된 제품에 적용될 정도로 안정화된 것은 2014년 중반 경이다.
1.1.6.1 사양
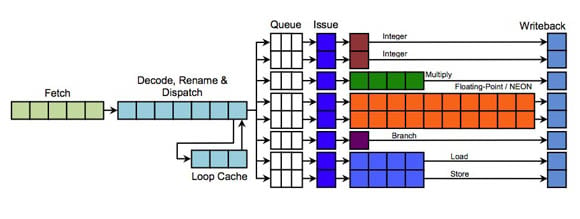
크고 아름답다
- 정수-15 / 부동 소수점- 17~25단계 파이프라인
- 한 사이클에 3개의 명령어 디코더 - 128k
- 명령어 발행 어레이 개수 = 5
- Issue명령 분배기 5개가 각 1~2개씩 총 8라인
- 내장 L2 Cache 통합, 분배식 입력
연산 모듈은 총 8개 (A~E)
- A1 - 정수연산(덧/뺄셈)(out)
- A2 - 정수연산(덧/뺄셈)(out)
- B - 정수 연산(곱/나눗샘)(out)
- C1 - NEONvfp (out)
- C2 - NEONvfp (out)
- D - branch(분기 예측)
- E1 - load/store
- E2 - load/store
확실하게 기존 ARM의 CPU 아키텍처보다 파이프라인이 대폭 복잡해진 것을 알 수 있다. Cortex-A9 대비 명령어 디코더의 개수가 1개 더 늘어나서 3개를 가지고 있으며 각 연산 유닛의 파트마다 각각의 독립적인 발행 어레이와 명령 분배기를 가지는 구조로써 Cortex-A9 대비 2배로 연산 유닛이 증가하고 이 것을 효율적으로 이용하도록 되어있다. Cortex-A9가 최대 발행 능력이 떨어져서 모든 모듈을 한번에 동작할 수 없었지만 Cortex-A15는 한번에 8개 유닛을 모두 사용할 수 있다고 한다.
기본적인 ALU의 성능이 강화되었고 곱셈과 나눗셈 전용의 ALU가 추가되었다. 또한 모든 연산 유닛의 비 순차적 처리 지원과 분기 예측기(Branch Predictor)를 내장하고 있다.
L2 Cache를 ARMv7-A 명령어셋 기반 Cortex-A 시리즈 중 최초로 아키텍처 안에 내장하였으며 통합된 하나의 거대 L2 Cache는 각 코어로부터 직접적으로 리소스를 주고 받을 수 있다. 이는 Cortex-A9에서 아키텍처와 외장 L2 Cache가 컨트롤러를 통해 한 단계 연결되었던 설계에 비해서 개선된 구조이다.
1.1.7 Cortex-A17

2014년 2월에 발표된 A 라인업 중 마지막 32비트 기반 ARMv7-A 프로세서이다.
라인업의 이름으로는 Cortex-A15의 상위 라인업인데 정작 A17은 A12의 리네이밍 제품으로[3] 제품 스케일 등은 오히려 Cortex-A15보다도 작다고 한다. 다만 아키텍처 설계 최적화가 잘되어서 성능은 A15와도 비슷한 수준이라고. Cortex-A15와 마찬가지로 Cortex-A7 아키텍처와 조합해서 big.LITTLE을 지원한다고 한다. 전체적인 성능은 Cortex A9보다 60%향상.
과거 하이엔드 프로세서였던 Cortex-A15는 초기 양산이 힘들었기 때문에 이 문제를 극복하지 못한 SoC 제작사들은 Cortex-A15를 포기하고 다른 방법을 찾았다. Cortex-A9 R4같은 기존 프로세서의 최신 리비전 버전을 사용하거나 Cortex-A7을 쿼드코어 2모듈 구조로 8코어까지 묶는 등 여러가지 참신한방법으로 문제점을 우회했다. A15의 양산과 보급을 성공적으로 한 업체는 겨우 삼성전자와 엔비디아 뿐이며 그나마 엔비디아는 AP 업계 내 지위가 미약하기 때문에 결국 사실상 삼성전자가 유일하게 된 상황이다. 결과적으로 Cortex-A15를 제대로 채택한 업체는 거의 없다.
출시 초기에는 64비트 지원의 ARMv8-A로 시장의 하이엔드 주력이 넘어가는 2014~2015년도 시점에서 미들레인지 정도의 성능으로 시장 포지셔닝이 가능할 것으로 예상되었다. Cortex-A15는 양산 문제가 있었고 새로 기획된 ARMv8-A 기반 Cortex-A57 프로세서도 이 문제를 피해갈 수는 없었다고 보았기 때문에 미들레인지 용으로 기존 여러가지 문제가 많은A15로는 부족하다고 판단했다. 그래서 Cortex-A17은 Cortex-A57을 준비하는 단계에서 사용할 Plan-B 라인업이라고도 볼 수 있다.
하지만 시장 상황은 2014년부터 빠르게 64비트로 전환되었고, Cortex-A17은 초기에 예상한 것과는 달리 입지가 더 좁아졌다. 2014년도 기준으로 64비트 구조의 Cortex-A53이 오히려 하이엔드인 Cortex-A57보다도 더욱 공격적으로 시장에 진입하면서 엔트리급에서 미들레인지, 심지어는 일부 하이엔드 영역까지 Cortex-A53의 고클럭 버전이 선점해 버리는 기염을 토하는 상황이 벌어졌기 때문이다.
Cortex-A17 아키텍처가 적용되어 시장에 첫 출시된 제품은 미디어텍의 MT6595로 Cortex-A7과 ARM big.LITTLE 솔루션으로 구성되었다.
1.1.7.1 사양
1.2 ARMv8-A
1.2.1 Cortex-A30 시리즈
1.2.1.1 Cortex-A35

ARMv8-A 명령어셋 기반 CPU이며 Cortex-A5와 A7의 포지션을 잇는 후속작이다. 해당 제품의 등장으로 LITTLE 치고는 성능이 지나치게 좋은 Cortex-A53이 미들레인지로 자리매김 하게 되었다.
현존 64비트 ARM 프로세서 중 전성비가 가장 높음과 동시에 다이 면적을 축소하여 비용을 절감시킨 프로세서이며 ARM 사의 주장에 따르면 28nm 공정 기준 90mW로 1GHz까지도 가능하다고 한다. 동시대의 다른 프로세서와 비교하면 ARM Cortex-A57 2.1GHz(14LPE)가 풀 로드 시 코어당 1.3W의 전력 소모, Cortex-A72 2.3GHz(16FF+)가 1.5W의 전력 소모, Cortex-A53@1.5GHz가 14nm 공정에서 200mW의 전력 소모를 보여준다. A57이나 A72는 물론, 그동안 리틀 코어를 담당했던 A53에 비해서도 매우 전성비가 좋은 편이다. 물론 이는 폴락의 법칙과도 관련 있는 부분이기도 하지만...
Cortex-A53과 ARM big.LITTLE 솔루션으로 구성이 가능하다. A72와도 가능한 모양.
1.2.1.1.1 사양


Cortex-A7 대비 개선점은
- 효율성 극대화를 위해 명령어 페치 유닛 재설계.
- 메모리 스트리밍 퍼포먼스에서 고성능 L1, L2 메모리 서브시스템 결과 최대 3.75배의 향상.
- 지역 고효율 NEON, 부동 소수점 파이프라인으로 부동 소수점과 DSP 작업 성능 향상
- 새로운 전력 관리 기술 지원
Cortex-A35는 8스테이지의 파이프라인을 가지고 있고 성능은 A7 대비 정수 연산에선 1.06배, 부동 소수점 연산에선 1.36배, 브라우징에선 1.16배, 긱벤치 MPI에선 1.4배의 성능 향상이 있다.
두 번째 사진에서 알 수 있듯이 엄청나게 유연한 설계가 가능하다. 28nm 쿼드 코어 구성에서 10배 더 작은 싱글 코어 구성까지 가능한 정도.
1.2.1.2 Cortex-A32

2016년 2월 22일에 발표된 Cortex-A 라인업중 가장 최신의 프로세서이다. ARMv8-A 명령어셋을 내장하였으나 특이하게도 AArch32만 지원하고 AArch64는 지원하지 않는다. 즉 64비트 프로세서가 아니다.
64비트를 포기한 프로세서답게 Cortex-A 라인업 중에서 최고의 전성비를 자랑하며 MCU급의 소형 임베디드 분야 중 고스펙 OS, 즉 리눅스나 안드로이드, 윈도우즈 등이 필요한 시장을 타겟으로 삼고 있다.
1.2.1.2.1 성능[4]

대체로 전세대의 Cortex-A5 대비 30% 이상, Cortex-A7과 비교해도 5~25% 높은 성능을 보여주며 제작사의 주장으로는 10년 전의 Cortex-A9와 유사한 성능이라고 한다. 위의 그림에서 스트리밍과 암/복호화에서 5배수 이상의 성능향상을 보여주는 것은 NEON SIMD 유닛의 성능 향상과 전용 암/복호화 명령어셋-하드웨어에 의한 것임을 상기할 필요가 있다.
전성비 역시 Cortex-A5와 Cortex-A7 대비 각각 30%와 25% 이상 향상된 것으로 알려졌다.
1.2.2 Cortex-A50 시리즈
1.2.2.1 Cortex-A53

64비트 ARM CPU의 실질적 주역이자 64비트 ARM의 시대를 적어도 1년은 앞당긴 1등 공신.
적절한 시점에 적절한 성능으로 적절한 가격에 나온 적절하3 의 SoC 업계판 제품.
땜빵이지만 괜찮았던 SoC판 T-62
원래는 ARMv8-A 명령어셋 기반의 CPU로 Cortex-A57/72와 ARM big.LITTLE 솔루션의 LITTLE 역할을 담당하도록 구성하거나 단독으로도 사용 가능하도록 기획된 제품으로 발표 초기에는 ARM 역사상 최강이자 최초의 64비트 프로세서가 될 예정이었던 Cortex-A57의 들러리 정도로 생각된 CPU였다.
따라서 관련 업계는 A53을 단독 솔루션으로는 크게 생각 안하는 분위기에서 64비트에 관심있는 업체들은 A57을 위주로 제품전략을 짜고 중저가 라인업의 업체들은 64비트의 본격적인 도입 시기는 2015년이나 될 걸로 예상하고 그냥 기존에 써먹었던 A9나 A7을 재탕하거나 새로 나온 A17 정도에 관심을 두면서 다가오는 2014년도의 제품 라인업을 구상하고 있을 즈음...
애플이 2013년 9월 느닷없이 64비트 기반 ARM CPU가 모바일 사상 최초로 탑재된 아이폰 5s를 시장에 냅다 투척했다!
갑자기 로드맵상으로 1년이 앞당겨진 64비트 시대 도래에 당황한 업계와 업체들은 그동안 개발해 왔던 로드맵들을 갈아엎기 시작하면서 롸잇 나우!! 얼른!! 현기증 난다고 대안을 찾아 헤메기 시작하는데. 대안용 64비트를 찾기 시작하자마자 눈에 들어오는게 LITTLE 컨셉으로 만들어져서 가격도 착하고 구조도 간단해서 바로 적용하기 쉬운데다가 이미 설계가 완비된 Cortex-A53.
결국 2014년도와 그 이후의 시장은 다음과 같은 분위기로 흘러가게 되었는데...
"싸구려 리틀 나부랭이라는 그딴 소리 집어치워! 32비트 OS를 깔아놓고 64비트라고 우겨도 상관없으니까 당장 64비트 AP를 내놔!"
그리고 2014년도 이후로 AP업계는 대리틀시대를 맞이하게 되었으니... 이하생략.
그런데 일단 급하게 도입한 아키텍처라서 처음에는 다분히 땜빵용으로 기획되기는 하였으나 태생적으로 중급형 수준까지도 일부 커버하는 것을 목표로 했던 아키텍처였고 여기에 저전력설계가 아닌 고성능설계를 적용해서 클럭까지 2GHz수준으로 올려버린 결과... 중급형 일부 뿐만이 아니라 중급형 전체를 아우를 수 있는 실력을 발휘하게 된다. 즉 고성능설계의 A57을 big으로 박고 저전력설계의 A53을 LITTLE로 박은 옥타코어 구성이 유행하게 된 것. 대표적으로 퀄컴 스냅드래곤 808 MSM8992, 퀄컴 스냅드래곤 810 MSM8994, 삼성 엑시노스 7 Octa(5433, 7420)등이 있다.
또한, 자체적인 성능 역시 중급형 CPU로 충분하기에 중급형 AP에 탑재되는 경우도 있다. 대표적으로 퀄컴 스냅드래곤 410 MSM8916, 퀄컴 스냅드래곤 615 MSM8939, 미디어텍 MT6795, 삼성 엑시노스 7580 등이 있다.
화웨이의 Krin920은 A53의 클럭을 2.0GHz까지 올리고서는 A53e라는 자체 코드명을 내세웠다. 물론 클럭을 올려도 내용물은 그게 그거지만
가장 많이 사용되는 모바일 CPU 벤치마크인 GeekBench의 성능을 기준으로 A53의 성능은 1GHz내외의 저클럭 에서는 A7보다 살짝 높고, A9와 동급의 클럭당 성능을 보여준다.[5] 다만 클럭을 높임에 따라서, Krait이나 A15와 비슷한 성능비를 보여줄 만큼 클럭에 따른 성능 차이가 크다.
참고로 기린 950 벤치마크의 측정된 전력 소모량에서 보여준 결과로는 28nm HPC + 2.0GHz가 570mW를, 1.5GHz가 350mW를 소비한다. 또 28nm HPM + 1.7GHz에선 400mW, 20nm SoC + 1.6GHz는 470mW[6], TSMC의 16nm FF+ 공정에서 1.8GHz가 164mW를 소비한다.
1.2.2.2 Cortex-A57
{kind=link}
ARMv8-A 명령어셋 기반의 CPU로 Cortex-A53과 ARM big.LITTLE 솔루션으로 구성이 가능하다. 대표적으로 퀄컴 스냅드래곤 808 MSM8992, 퀄컴 스냅드래곤 810 MSM8994, 삼성 엑시노스 7 Octa 5433, 삼성 엑시노스 7 Octa 7420 등이 있다.
하지만 해당 코어가 탑재된 퀄컴 스냅드래곤 810 MSM8994가 화룡810 사건으로 회자되는 전대미문 수준의 발열 문제를 일으켰고, 삼성전자는 이 코어의 최적화를 위해서 최적의 전성비를 낼 수 있는 세팅을 직접 일일이 찾아서 엑시노스 7 Octa 5433을 내놓았다고 주장했으며, 삼성과 퀄컴 이외에는 이 코어를 탑재한 AP를 만든 제조사가 없다는 점, 또한 ARM Holdings가 유달리 빨리 Cortex-A72를 준비했으며, 또한 Cortex-A72가 조기 공개되자 삼성과 퀄컴 이외에도 미디어텍과 다른 유수의 제조사들이 Cortex-A72의 탑재에 적극적으로 나섰다는 점을 이유로 들어서 스냅드래곤 810의 발열과 성능저하 문제는 퀄컴의 커스텀과 TSMC 20nm SoC 생산공정 최적화 단계 상에서 난 삑사리(...) 차원의 문제가 아니고 Cortex-A57 코어 자체에 기본적인 결함이 존재하는 것을 의심하는 주장이 존재한다.
여담으로 28nm Cortex-A15와 20nm Cortex-A57의 전력 소모량은 비슷하다. 공정이 깡패다. 같은 공정이라면 Cortex-A57이 Cortex-A15 보다 전력소모가 많다
1.2.2.3 공통사양
- 64비트 지원(AArch64)
- 32비트 ARMv7-A 명령어와 100% 하위호환
- TrustZone® 보안 기술
- NEON™ Advanced SIMD
- DSP & SIMD 확장
- VFPv4 부동소숫점 연산
- 하드웨어 가상화 지원
1.2.2.4 성능
파일:ChO9Yji.jpg
Cortex-A53은 전체적으로 Cortex-A9와 비슷하거나 향상된 성능을 보이며 Cortex-A57은 Cortex-A53의 약 1.5배에서 2배의 성능을 보인다.
{kind=link}
500px
Cortex-A57 프로세서와 Cortex-A15 프로세서의 비교 그래프.
{kind=link}
1.2.3 Cortex-A70 시리즈
1.2.3.1 Cortex-A72
{kind=link}
2015년 2월 5일에 공개된 ARM Cortex-A 시리즈의 차세대 고성능 CPU이다. ARMv8-A 명령어셋 기반의 CPU로 Cortex-A53과 ARM big.LITTLE 솔루션으로 구성이 가능하다.
기본적으로 2014년 말에 첫 제품이 양산된 Cortex-A57의 최적화 혹은 업그레이드 제품으로 분류할 수 있으며 기본적인 구조는 대동소이한 것으로 알려져 있었지만...
사실은 엄연한 Cortex-A57의 차세대 제품이다. 이런 오해가 생기게 된 원인은 Cortex-A72가 아키텍처가 발표된 2015년인데 비해 1년도 안되는 이례적으로 빠른 속도로 실제품이 시장에 출시된 것에 기인한다. 통상 ARM제품의 개발주기가 아키텍처 발표 후 3년 정도 후에 초기 제품이 출시되는 패턴으로 2012년에 발표된 Cortex-A57의 실제품 양산은 2014년말이라서 이러한 주기와 잘 일치하였으나 Cortex-A72는 그러한 관례를 깬 것에서 오해의 소지가 생긴 것.
성능상으로도 개발사 주장에 따르면 20%정도 향상되었으니 후속 제품으로서의 포지션 자체는 확고한 셈이다.
특이하게도 Cortex-A57이 TSMC의 20nm 공정과 삼성S.LSI의 14nm LPE 공정을 지원[7]했던 데 비해 보다 신형인 Cortex-A72는 최신형의 TSMC 16nmFF+ 공정뿐만 아니라 구형인 TSMC 28nm공정을 지원하는 기행역주행을 벌였다.
하지만 이러한 기행 덕분에 상대적으로 저렴한 28nm 공정에서 제조되는 미들레인지 AP 제품군 에서도 Cortex-A72 쿼드 구성이라는 준 하이엔드급 구성이 가능해지면서 Cortex-A72의 시장 입지가 크게 넓어졌다.
성능 자체도 16nmFF+에서 생산되는 제품은 강력한 클럭으로 인해 하이엔드-플래그쉽으로서의 역할을 충분히 감당할 수 있는 상황인지라 커스텀 아키텍처를 개발할 여력이 되는 퀄컴이나 삼성같은 대규모 Tier-1급 AP 개발 업체가 아닌 하이실리콘, 미디어텍, LG등과 같은 업체들의 경우 하이엔드 영역의 AP개발을 가능케 해 주는 여러모로 필수요소 같은 존재다.
1.2.3.2 성능
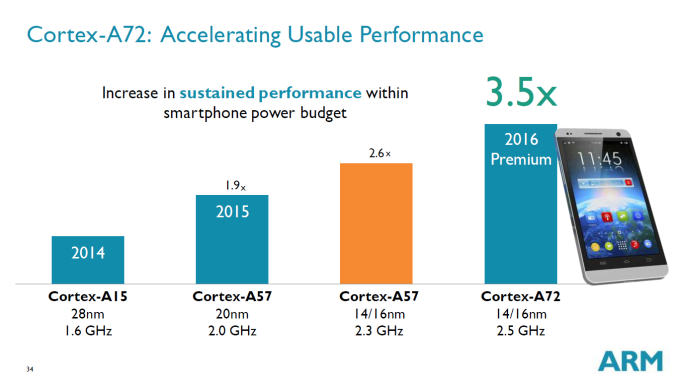
ARM의 발표에 의하면, Cortex-A57 대비 동클럭당 약 23%, Cortex-A15의 약 3.5배의 성능을 보여준다고 한다.
클럭을 정규화했을 경우의 성능 비율은 각각 1.0:1.5:1.8:2.2 미묘하게 같은 A57사이에서도 성능 차이가 벌어진다.
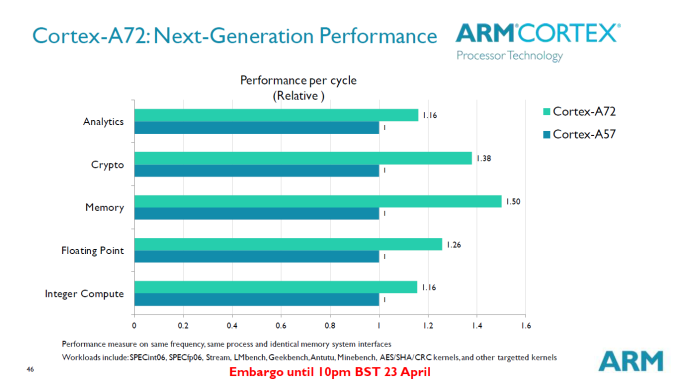
일반연산에서 16%, 암호화에서 38%, 메모리I/O에서 50%, 실수연산 26%, 정수연산에서 16% 향상되었다고 발표되었으며 전반적으로 23% 향상이라는 위의 내용과 대체로 일치한다.
1.2.3.3 Cortex-A73


Cortex-A72의 개선형으로 발표되었다.
1.2.3.4 성능

A73은 A72의 개선된 버전이며 면적당 성능비가 40% 향상되고 20%이상 전력효율이 증가하였으며 10nm공정에 최적화 되어있다고 발표했다.
2 커스텀 아키텍처
ARM에서 직접 설계한 아키텍처가 아닌 명령어 셋을 직접 이용해서 제작한 커스텀 아키텍처 목록이다. ARM에게 IP 라이센스를 취득해서 제작된다.
같은 명령어를 사용하기 때문에 구조 상으로 Cortex-A 시리즈와 유사하나, 일반적인 Cortex-A 시리즈를 그대로 사용하는 AP와는 다르게 AP 설계사에서 독자적으로 개발한 부분의 비율이 높다는 것이 특징이다.
관련 커뮤니티에서 커스텀 아키텍처의 본류를 Cortex-A 시리즈에서 찾으려는 경향이 있지만, 엄밀히 말해서 명령어 셋을 직접 이용해서 만드는 것이기 때문에 Cortex-A 시리즈에서 본류를 찾는 것은 적절하지 않다. 때문에 적절히 '비슷한 성능의 Cortex-A 시리즈가 이 것'이라는 사실만 알고 있는 정도로 생각해야 한다.
2.1 ARMv7 기반
2.1.1 퀄컴
2.1.1.1 스콜피온
퀄컴이 자사 AP 브랜드인 스냅드래곤을 런칭하면서 2009년, 스냅드래곤 S1 QSD8x50에 사용한 ARMv7-A 기반의 커스텀 아키텍처. 이후 스냅드래곤 S2 소속 모바일 AP와 스냅드래곤 S3 소속 모바일 AP에도 코어 리비전되어 사용되었다.
본가 ARM 라인업에 대응하는 아키텍처로는 Cortex-A8과 Cortex-A9로 볼 수 있다. 2009년 말 첫 시제품이 HTC의 HD2에 탑재되어 주목을 받았다. ARM 기반 CPU로는 최초로 1GHz에 도달했기 때문이다. 당시 경쟁 CPU 아키텍처는 ARMv6 기반의 ARM11 아키텍처 및 ARMv7 기반의 Cortex-A8이었다. 이 때의 Cortex-A8 기반 AP는 TI의 OMAP 3 시리즈와 삼성전자의 엑시노스 3110 초기 모델 뿐이었고 800MHz 내외의 클럭을 가지고 있었다.
특히,국내에서는 이 시기에 옴니아 II와 아이폰 3GS의 참으로 어처구니 없는 양강구도를 가지고 있었다. 이 와중에 국내의 소수 PPC[8]유저들은 HD2를 주목했다. 1GHz라는 당시 최고클럭의 CPU와 Windows Mobile을 가지고도 충분한 퍼포먼스를 뿜어내는 HTC의 최적화 능력[9]과 화려한 hTC Sense는 Windows Mobile 스마트폰이라 볼 수 없는 퍼포먼스를 보여줬고, 옴니아 II와 대조되면서 초기 퀄컴 스냅드래곤의 이미지를 좋은 쪽으로 부각시켰다. 그래 지금까지는...
2010년 이후로 오픈 소스인 안드로이드를 사용한 스마트폰이 주로 출시되었고, 시장의 파이가 커짐에 따라서 ARM에게 라이센스를 취득한 AP 개발업체가 증가, 퀄컴 스냅드래곤은 초기의 모습과는 달리 하락세를 걷기 시작했다.
Cortex-A8을 사용한 TI의 OMAP과 ARM의 권고를 무시하고 코어 커스텀까지 강행해서 1 GHz의 클럭을 돌파[10]한 삼성전자의 엑시노스 3110 같은 경쟁 AP에게 성능적으로 밀리기 시작했다. 이후 퀄컴 스냅드래곤 S2는 Scorpion 아키텍처를 일부 개선하고 CPU 클럭을 1.4GHz까지 상승시켰지만, Cortex-A8과의 경쟁에서는 완전히 패배해 버린다. 당시 성능 기준은 게임이 가장 큰 비중을 차지하고 있었고 당시 스냅드래곤에 들어간 Adreno GPU가 경쟁 AP에 들어간 Imagination Technologies의 PowerVR SGX 5 시리즈에 비해서 성능과 최적화 모두가 부족했기 때문이었다. 스마트폰 시장을 새로이 개척한 애플의 아이폰 시리즈의 AP가 전통적으로 PowerVR GPU를 사용하고 있었고, 초기 안드로이드에 대한 이해가 부족한 어플 개발자들이 모델링의 최적화 과정 없이 이식해 온 게임들의 대다수는 같은 PowerVR GPU를 사용하는 기기에서 원활하게 돌아갔던 것에 비해서 Adreno라는 자체 GPU를 사용했던 퀄컴의 AP에서는 원래 성능을 내기 어려웠다.
2011년에는 이러한 현상이 정점을 찍어버렸다. Cortex-A8의 후속 아키텍처인 Cortex-A9 기반의 AP가 속속 출시되었다. 문제는 Cortex-A9가 멀티코어를 지원하기 시작하면서 TI OMAP 4 시리즈와 삼성전자의 엑시노스 4210, NVIDIA의 Tegra 2 시리즈가 전부 Cortex-A9 기반의 듀얼코어를 사용하기 시작했고, 퀄컴에서는 이에 대항하기 위해 Scorpion을 소폭 개량해 멀티코어를 지원하게 만들고, L2 Cache의 용량을 증가시켜 퀄컴 스냅드래곤 S3에 탑재했다. 파이프라인의 수를 늘려서 CPU 클럭도 1.5GHz로 기존 스마트폰에 들어가 출시된 모델 대비 약 50% 정도 상승시켰다. 그러나 IPC 상의 개선이나 공정 미세화가 동반되지 않는 상황에서 올리다 보니 불타는 발열의 스냅드레곤, 스냅드레기같은 명성을 확고히 하는데 일조하였다.
2011년 말에 우후죽순으로 출시된 1세대 LTE 지원 스마트폰에 많이 사용되었다. 당시에 나왔던 LTE 통신 모뎀은 전부 데이터 통신만 지원했고, 퀄컴의 1세대 LTE 통신 모뎀 MDM9200/9600도 스냅드래곤 S3과는 별개의 데이터 통신용 칩셋이었다. 스냅드래곤 S3 APQ8060은 통신 모뎀을 내장하지 않았지만, MDM9200/9600 모뎀과 같이 사용하면 원래 이론상 불가능한 GSM과 WCDMA 음성통화가 지원되었다. 사실상 이 조합이 당시 사용 가능했던 유일한 LTE 및 3G 음성 통화가 가능한 AP 조합이었다. VoLTE는 아직 시범 서비스도 실시하지 않던 시기였다.
CDMA의 경우 CDMA 통신 모뎀이 내장된 퀄컴 스냅드래곤 S3 MSM8660과 같이 사용하여 통신을 따로 처리했다. 약간의 예외로 CDMA+LTE 조합의 네트워크에서 스냅드래곤을 사용하지 않는 퀄컴/비아의 CDMA 칩+삼성의 LTE 칩 같은 조합이 소수 있었지만, 출시 기기들의 배터리 소비 문제가 심각하여 이후에는 볼 수 없게 되었다. 이 조합을 사용한 기계가 갤럭시 넥서스의 LTE 지원 모델인데, WCDMA 지원 모델에 비해서 기본 배터리 용량이 더 컸다.
이렇게 기기 내부에 칩셋이 많아져서 커짐에 따라 낮은 해상도로는 경쟁력이 없다고 판단한 스마트폰 제조사들이 기존 WVGA(480 x 800), FWVGA(480 x 854)보다 고 해상도인 HD 720p(1280 x 720)를 채택하면서 엄청난 발열의 시너지 효과를 보여주었다. 해상도가 높을수록 디스플레이 전력 소모율이 높아진다. 거기에 통신 모뎀과 AP가 분리된 상황이니 기존 통신 모뎀이 통합된 경우보다 전력 소모율이 높다. 하물며 이게 HD 720p를 지원하지만 감당하기 버거워한 퀄컴 스냅드래곤 S3다. 더 이상의 자세한 설명은 생략한다.
때문에 Scorpion 아키텍처는 모바일 AP 시장에서 아키텍처의 개량에 뒤처지면 시장에서 어떠한 평가를 받는지를 생생히 보여주는 본보기가 되었다.
2.1.1.1.1 사양
- 10~12단계 파이프라인
- 한 사이클에 2개의 명령어 디코더
- Issue 분배기가 3라인 파견
- 부분 비 순차적 처리 지원
- Neon 유닛이 연산 모듈에 포함
- 멀티 코어 구성 가능
Scorpion의 자세한 구조는 잘 알려지지 않았다. 다만 알려져 있는 정보상으로는 위에서 신나게 까인것과 다르게 상당히 진보한 구조의 아키텍처로서 ARMv7-A 기반의 첫 아키텍처인 Cortex-A8과 비교시에도 상당한 우위점이 많다. 우려먹어서 문제지..
Cortex-A8에서는 Neon/vfp SIMD 모듈을 외부에 옵션으로 부착하는 형태였는데, Scorpion에서는 처음부터 연산 유닛화하여 파이프라인에 내장하였다. 연산모듈에 알맞게 명령어를 분배하는 Issue 분배기도 비 순차적 처리를 지원하며, 초기 모델부터 소량의[11] L2 캐시를 내장했다. 그리고 처음부터 멀티코어화를 고려해서 개발했기 때문인지 아키텍처를 크게 변경할 필요 없이 듀얼 코어까지 지원한다. 이 모든 것이 Cortex-A 시리즈에서는 Cortex-A9부터 지원된 부분이다.
이 외에 Cortex-A9보다 나은 점도 존재한다. Cortex-A9의 Neon 유닛은 64KB 기반인 반면, 이쪽은 128KB 기반이다. 이 때문에 멀티미디어 기능에 많이 사용되는 부동소수점 연산에서 우위를 점한다. 다만 이것이 시장에서 실제 강점으로 크게 활용되지는 못했는데, SoC의 발전에 따라 AP 다이 안에 추가로 GPU 코어를 탑재하는 것이 일반화되면서 상대적으로 느린 CPU 가속보다는 GPU 가속을 활용하는 것이 성능면에서 이점이 컸기 때문이다.
결론적으로 매우 괜찮은 아키텍처였으나, 시장의 변화와 경쟁에서 밀리고 결국 오명을 다 뒤집어쓴 매우 대표적인 사례가 되었다. 시작은 매우 훌륭했으며 중반기에는 중박, 후반기에는 쪽박이라는 다양한 시장의 평가가 인상적.
2.1.1.2 크레이트
퀄컴이 자사 AP 브랜드인 스냅드래곤의 2012년 플래그십 AP인 스냅드래곤 S4 Plus MSM8960에 사용한 ARMv7-A 기반의 커스텀 아키텍처. Scorpion의 후속작으로 이후 기존 Krait는 Krait 200으로 재명명되고 Krait 300, Krait 400, Krait 450으로 코어 리비전이 진행되어 2014년 말 스냅드래곤 805 APQ8084까지 사용되었다.
수의 의미는 순정 ARMv7-A 명령어 셋 기반의 아키텍처보다 리비전 된 정도를 의미한다. 200에서 300은 클럭당 10%에서 최대 30% 정도의 성능 향상이 있었으며 300에서 400의 경우에는 최대 클럭이 20% 더 상승되어서 모바일 AP 최초로 CPU 클럭이 2GHz를 돌파하게 되었다.[12]
이전에는 'ARM Cortex-A9 베이스 + ARM Cortex-A15 명령어 추가'의 방식으로 만들어졌다고 퀄컴 스냅드래곤 항목에 서술 되어 있었는데, 이건 반만 맞고 반은 틀린 설명이다. 굳이 꼭 집어서 ARM Cortex-A9를 커스텀한거다, ARM Cortex-A15를 커스텀한거다 말할 수는 없는데, Qualcomm Scorpion부터 시작된 퀄컴의 자체적인 주력 CPU는 죄다 아키텍처 라이센스를 딴 다음 ARMv7-A 명령어 세트 기반으로 커스텀한 아키텍처다. 또한 Krait와 ARM Cortex-A15는 ARM 기반 프로세서의 발전 방향이 비슷하기 때문에 대략적인 구조가 비슷할 뿐이지 여러모로 차이가 많다.
굳이 파이프라인 레벨에서 비교해본다면 Krait는 A15보다는 A9에 비슷한 구조이다. A9 대비 디코더의 개수와 연산 모듈은 늘었지만, Issue 분배기의 한계로 늘어난 연산 모듈을 한번에 활용하는것이 불가하며,이것도 A9에서 지적되었던 문제이다. A15와 비슷한점은 캐쉬를 코어 내에 내장했다는 것 정도다.
삼성전자나 엔비디아 등 경쟁사들이 ARMv8-A기반의 Cortex-A53과 Cortex-A57을 이용한 차세대 AP를 2014년 상반기를 목표로 개발하고 있는 상황에서 생산사인 TSMC의 미세공정의 이원화가 늦어지는 상황[13]에다 과거 Scorpion 아키텍처의 전철을 밟아 Krait 아키텍처를 개선하고 클럭을 상승시키는 쪽으로 갈 것이라는 예상이 나오고 있다.[14] 다만, 퀄컴이 이전의 사례를 답습했다면 Krait의 후속 아키텍처로 승부를 볼 것이라는 이야기도 있다.
여담이지만 Krait 400까지는 Cortex-A15보다 IPC가 낮다.
2.1.1.2.1 사양

- 한 사이클의 3개의 명령어 디코더
- 명령어 발행 어레이 개수 = 1
- ISSUE명령 분배기 1개가 4라인 한번에 파견은 4개
연산 모듈은 총 7개
A1 - ?[15]
A2 - ?
B1 - ?
C1 - ?
C2 - ?
D1 - NEON/vfp (128k)
D2 - NEON/vfp (128k)
동시대 경쟁 아키텍처인 Cortex-A9와 비교 시에 명령어 디코더가 1개 늘었다. 다만 총 연산 모듈은 7개인 것에 반해 Issue 명령 분배기의 최대 파견량이 최대 4개로 Krait가 Cortex-A15보다 Cortex-A9에 가까운 아키텍처라는 것을 알 수 있다. Cortex-A15는 Issue 명령 분배기 자체가 5개, 한번의 파견량은 8개로써 8개의 연산 모듈을 모두 사용할 수 있다.

또한 Cortex-A9의 외장 L2 캐시에 비해서 Krait 아키텍처는 효율이 더 좋은 내장형의 L2 캐시를 가지고 있지만, 각각의 코어가 비교적 소량의 L2 캐시를 가지고 있으며 하나의 대형 캐시를 가지고 있는 Cortex-A15나 Cortex-A12에 비해서 상황에 따른 효용성이 떨어진다. 즉 하나의 코어에 작업이 몰리더라도 한개의 코어는 제한적인 용량의 캐시만을 사용할 수 있고 이는 모든 코어가 하나의 대용량 캐시를 사용하는 방식에 비해서 불리하다. 이는 Krait 아키텍처 자체가 비동기식 구조를 가지고 있어서 각각의 코어가 별개로 운용되는것을 전제로 설계되었기에 나타나는 문제이다.
2.1.2 애플
2.1.2.1 스위프트
애플이 2012년 타겟 자체 AP인 Apple A6 APL0598에 사용한 ARMv7s 기반의 커스텀 아키텍처. 사용된 명령어 셋 자체도 ARMv7-A 명령어 셋이 커스터마이징된 ARMv7s 명령어셋 기반으로 만들어졌다. 상위 문단의 명칭이 ARMv7인 이유가 이거다 이후 Apple A6 APL5598에도 사용되었다.
2.1.2.1.1 사양

- 한 사이클에 3개의 명령어 디코더
- 명령어 발행 어레이(dispatch) 개수 = 1
- Issue 명령 분배기 1개가 5라인 한번에 파견은 5개
연산 모듈은 총 5개 (A~E)
- A - ALU(out[16])-정수연산 덧/뺄셈
- B - ALU(out)-정수연산 덧/뺄샘/곱/나눗셈
- C - NEON/vfp (?)
- D - NEON/vfp (?)
- E - load/store - AGU
A9 대비 명령어 디코더의 개수와 연산 유닛의 수가 늘었다. 특히 Krait와 달리 A9 때부터 문제시 되었던 Issue분배기의 최대 파견량이 총 연산 유닛의 수보다 적어서 효율이 떨어진다는 점이 해소되었다. 현재 전체적인 평가는 Krait와 비슷한 성능으로 귀결.
2.2 ARMv8-A 기반
2.2.1 애플
2.2.1.1 사이클론
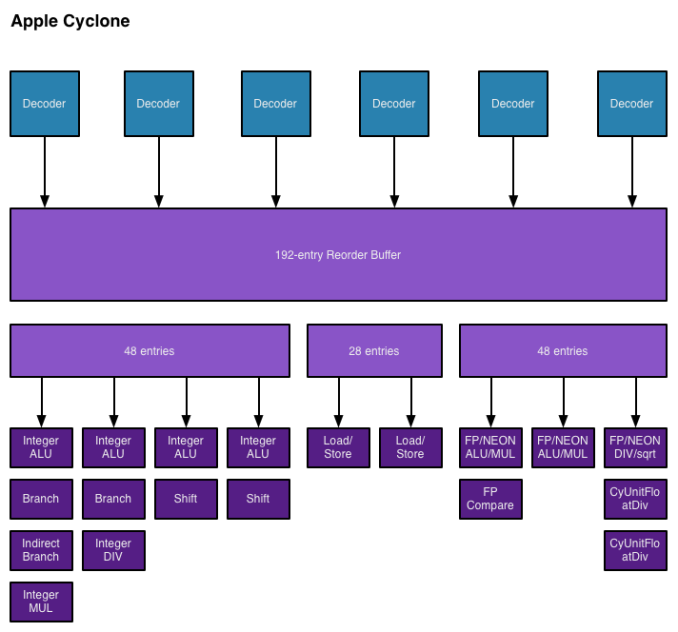
애플이 2013년 타겟 자체 AP인 Apple A7 APL0698에 사용한 ARMv8-A 기반의 커스텀 아키텍처. 스위프트의 후속작으로, 이후 Apple A7 APL5698에도 사용되었다.
애플은 아이폰 5s를 공개할 때 데스크탑 급 CPU라 소개했었지만 대개 스위프트의 발전형으로 추측했다. 그러나, 그 예상은 모조리 틀리게 되었다. 우선 Cyclone의 리오더 버퍼는 엔트리가 192개로 확 늘었는데, 이는 인텔의 하스웰과 같은 수준이라고 한다. 즉, 애플의 소개 설명은 틀린 말이 아니라는 것이다.
2.2.1.2 타이푼
애플이 2014년 타겟 자체 AP인 Apple A8 APL1011에 사용한 ARMv8-A 기반의 커스텀 아키텍처. Cyclone의 후속작이며 이후 Apple A8X APL1012에도 사용하였다.
2.2.1.3 트위스터
애플이 2015년 타겟 자체 AP인 Apple A9 APL0898 & APL1022에 사용한 ARMv8-A 기반의 커스텀 아키텍처. Typhoon의 후속작이며 이후 Apple A9X APL1021에도 사용되었다.
2.2.1.4 허리케인 & 제퍼
애플이 2016년 타겟 자체 AP인 Apple A10 Fusion APL1W24에 사용한 ARMv8-A 기반의 커스텀 아키텍처. Twister의 후속작이며 애플 AP 최초로 빅리틀이 적용되었다. 허리케인이 빅코어고 제퍼가 리틀코어다.
2.2.2 엔비디아
2.2.2.1 덴버
{kind=link}
엔비디아가 자사 AP 브랜드인 Tegra의 2014년 플래그십 AP인 Tegra K1 T132에 사용한 ARMv8-A 기반의 커스텀 아키텍처.
2014년 상반기 당시로서는 압도적인 성능을 보여주었다. 2015년 하반기 기준으로 보면 엄청 좋은 성능은 아니지만 싱글코어 성능은 Apple A9를 제외하고는 최강이긴 하다 싱글코어 점수 약 2200 점에 멀티코어 점수 약 4000 점으로 그 당시 모바일 AP들의 평균적인 멀티코어 점수가 약 3000 점 전후였던 것을 고려하면 최정상급의 성능을 자랑했다.
사실 덴버는 여기 있으면 좀 안되는 종류의 코어. 과거 크루소/에피시언 프로세서 처럼 코드 옵티마이져가 중간에 Denver를 ARM v8 명령어를 처리할 수 있게 바꿔주는 구조이다.(그래서 Nexus 9에서 보면 메모리가 2GB가 안된다. 코드 옵티마이져가 메모리를 먹고 있기 때문)
최초 설계를 x86 호환 코어로 준비하였으나 인텔과 x86 라이센싱을 너무 질질 끄는 바람에 그냥 ARM v8로 나왔다.
2.2.3 퀄컴
2.2.3.1 크라이오
퀄컴이 자사 AP 브랜드인 스냅드래곤의 2016년 플래그십 AP인 스냅드래곤 820 MSM8996에 사용한 ARMv8-A 기반의 커스텀 아키텍처. 크레이트 시리즈의 후속작으로 개발 코드네임은 'Taipan'.
2.2.4 삼성전자
2.2.4.1 엑시노스 M1
이 문단은 Samsung Exynos M1 · Samsung Mongoose(으)로 검색해도 들어올 수 있습니다.
삼성전자가 자사 AP 브랜드인 엑시노스의 2016년 플래그십 AP인 엑시노스 8890에 사용한 ARMv8-A 기반의 커스텀 아키텍처. 개발 코드네임은 'Mongoose'.[17]
퀄컴의 Qualcomm Scorpion, Qualcomm Krait 시리즈, Qualcomm Kryo, 애플의 Apple Swift, Apple Cyclone, 엔비디아의 NVIDIA Denver처럼 삼성전자에서 직접 ARMv8-A 기반으로 만든 CPU 아키텍처로, 개발 당시에는 GCC 5.0 정보를 통해 Exynos M1이라는 명칭으로 유출되었다고 한다. 이후 2015년 11월 12일, 해당 CPU를 탑재한 첫 번째 모바일 AP인 엑시노스 8890이 정식으로 공개되었다.
2016년 8월 22일, Hot Chips 28에서 정식으로 공개되었다. 분기 예측에 인텔, AMD 등이 사용하는 최신 분기 예측 시스템인 신경 네트워크 구조를 사용하였으며, 코어의 구조 자체도 ARM의 빅 코어들과는 꽤 차이가 난다는 것이 확인되었다.
- ↑ 굳이 언급하자면 ARM사의 Cortex-A 제품의 3단계 라인업은 사전에 설정된 라인업이라기 보다는 사후 정리에 가깝다. 예를 들어 Cortex-A9의 출시 시점에서는 아예 3단계 구분이 가능할 만큼 제품의 종류가 많지 않아서 Cortex-A9가 올라운드 플레이를 해야하는 상황이었고, Cortex-A7과 Cortex-A15의 빅-리틀 페어가 출현하는 시점에서는 오히려 빅과 리틀이라는 2단계 구분법이 더 합리적이더라는 측면도 있었기 때문.
- ↑ 밑에서 각 A,B,C로 지칭
- ↑ 2014년 10월 1일 ARM 홈페이지에서 공식적으로 Cortex-A12를 Cortex-A17 라인으로 편입시켰다.
- ↑ https://community.arm.com/groups/processors/blog/2016/02/23/introducing-cortex-a32-arm-s-smallest-lowest-power-armv8-a-processor-for-next-generation-32-bit-embedded-applications 를 참조할 것.
- ↑ 큰 차이가 없는 성능이기는 하지만, 엑시노스 5430 vs 5433을 비교해보면, 쿼드코어 기준 A53은 A7 대비 거의 2배의 전력소비가 있다. http://www.anandtech.com/show/8718/the-samsung-galaxy-note-4-exynos-review/4
- ↑ 스냅드래곤 810...
- ↑ 참고로 삼성 S.LSI의 14nm 공정 지원은 삼성측의 독자 지원에 가깝다. 파운드리 업계에서의 레퍼런스로서의 위상은 TSMC가 여전히 절대적이라서 ARM사가 TSMC측의 공정을 레퍼런스로 우선 지원하는 것이 이상한 일이 아니다.
- ↑ Pocket PC, 당시 일반인들에게는 생소한 WM기반의 PDA의 총칭한다.
- ↑ 이전부터 HTC는 마이크로소프트의 허락과 협조를 받아 Windows Mobile을 자체적으로 빌드한 결과물을 탑재했다.
- ↑ 무식한 오버클럭은 아니다. IPC와 공정 개선도 동반된 클럭 상승은 전형적인 비메모리의 성능 개선 방법이다.
- ↑ S1부터 인지는 확실하지 않다.
- ↑ 여담으로, 최초로 2GHz에 도달한 모바일 AP는 삼성전자의 엑시노스 5250이다.
- ↑ 현재, 모바일 AP 파운더리 시장의 큰 손인 애플이 자사의 AP를 위해 TSMC가 22nm 공정으로 전환하도록 자금 투입을 상당히 하고 있는 상황이다. 때문에 공정이 전환되어도 애플에 몰아줄 가능성이 높다.
- ↑ 현재 지금까지 알려진 로드맵상에서는 이쪽이 유력하다.
- ↑ 총 연산 유닛의 수와 Neon의 경우는 비교적 명확하나 자세한 내용은 불명이다. 현재 ALU와 AGU가 있을 것으로 추측된다.
- ↑ Out-of-order/비순차적 처리
- ↑ 실제 탑재 기기인 갤럭시 S7 & 갤럭시 S7 엣지의 커널 소스에는 그대로 Mongoose가 사용되고 있다. 약어로는 'MNGS'로 표기된다.