- 상위항목 : 언어 관련 정보
| 인도유럽어족 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 원시인구어† | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CENTUM 어군 | SATEM 어군 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 게르만어파 | 아나톨리아어파† | 이탈리아어파 | 켈트어파 | 토카리아어파† | 헬라어파 | 발트-슬라브어파 | 아르메니아어파 | 알바니아어파 | 인도이란어파 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 발트어파 | 슬라브어파 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 북게르만어군 | 서게르만어군 | 동게르만어군† | 라틴팔리스칸어군 | 오스칸움브리아어군† | 대륙켈트어군† | 도서켈트어군 | 동발트어군 | 서발트어군† | 동슬라브어군 | 서슬라브어군 | 남슬라브어군 | 누리스탄어군 | 다르드어군 | 이란어군 | 인도아리아어군 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 로망스어군 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 어군 위치가 비어있는 어파는 단일언어로 독립된 어파를 이루거나 소속된 제어들을 분류할 사료가 부족한 경우에 해당함. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 세부적인 어군 분류는 각 항목 참조. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| †가 있는것은 사멸된 어파 혹은 어군 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Indo-European languages
1 개요
한자식 줄임말로 인구어족(印歐語族)이라고 하는데, 이는 인도구라파어족(印度歐羅巴語族)의 줄임말이다. 사용인구수 기준으로 세계 최대의 어족[1]이며 학문적으로 연구되고 발견된 최초의 어족이다. 말그대로 인도~유럽에 걸쳐 쓰이며, 유럽인이 2차적으로 진출한 아메리카 등의 식민지에서도 쓰인다.[2]
2 역사
크게 두 가지 가설이 존재하는데 기원전 4천년대 러시아 남부의 흑해-카스피해에 걸친 초원지대에서 사용된 언어에서 출발했다는 steppe hypothesis와 약 8천년 전에서 9500년 전 아나톨리아의 농경민이 사용했던 언어에서 출발했다는 Anatolia hypothesis가 존재한다. steppe hypothesis는 재구된 원시인구어에서 계급/계층 분화와 관련된 어휘가 보이고 가축과 바퀴/수레와 관련된 어휘가 나타나는 것에 착안한 것이다. Anatolia hypothesis는 최초의 농경 문화의 발상지에 가까워 농경민의 인구 증가 및 이주를 언어 확장의 원동력으로 볼 수 있고, 신석기 문화의 확장이 고고학적으로 매우 명확한 변화를 유도하는 것에 착안한 것이다. 최근의 언어학/유전학/고고학 연구로 steppe hypothesis를 지지하는 여러 근거가 알려지게 되었다. 지금으로부터 4500년 전에서 6천년 전쯤부터 여러 언어로 갈라지기 시작해 총 400여 개의 언어로 분화했고Science, 오늘날 이 어족에 속하는 언어를 사용하는 사람의 수는 약 25억 명이나 된다. 영어로 PIE(Proto India-Europe language)라 불리는 조어(祖語) 원시인구어는 문자로 기록되지 않아서 정확히 알 수 없지만 후손격의 언어들로부터 역추적하여 재구성하는 연구가 꾸준히 진행되고 있다.
원시인구어에 대한 연구는 꽤 많이 진척되어 원시인구어 사전도 여럿이 존재하고 있다. 이렇게 어족을 설정하고 역추적-재구성을 연구하는 언어학의 분야를 비교언어학이라고 하는데, 비교언어학은 인도유럽제어(諸語)가 같은 어족임을 규명하는 과정에서 탄생하고 발전했다. 예를 들어, 인도유럽어 사용자들은 Dyēus Ph2tēr라는 하늘의 주신(主神)을 섬겼다. 여기서 Zeu pater를 호격으로 갖는 그리스 단어 제우스(Zeus)와 고 라틴어 Iovis pater[3]에서 온 라틴어 유피테르[4](Iupiter) 등이 나왔다. 하늘에 계신 우리 아버지라는 개념은 인류의 가장 오래된 신화 중 하나일지도 모르겠다.
인도유럽어족을 처음으로 발견, 연구한 사람은 1700년대에 영국의 인도 대법원장이었던 윌리엄 존스라는 사람이었다. 그 당시 영국과 인도 사이의 문화적인 갈등이 너무 커지자, 영국 정부에서는 아시아 문화에 대해 가장 자세히 알고 있는 사람을 인도로 보내기로 결정한다. 기록에 따르면 윌리엄 존스의 언어에 관한 먼치킨성을 보여주는데, 그는 대학에 입학하기도 전부터 고대 그리스어, 라틴어, 아랍어, 히브리어, 그리고 한문을 마스터했다고 한다! 그는 평생 13개의 언어를 완벽히 구사했으며, 28개의 언어를 번역할 수 있었다고 한다! 그는 인도로 파견된 뒤, 이곳의 문화를 이해하기 위해서는 인도인들의 고전과 신화를 알아야 한다며 산스크리트어까지 배운다.이게 사람이냐 그러던 중에 그는 산스크리트어의 어휘들이 영어, 라틴어 등과 굉장히 닮아있다는 것을 조금씩 알게되고, 영어와 라틴어 같은 유럽쪽의 일부 언어들의 공통조상이 바로 이 고대 산스크리트어가 아닐까 하는 생각을 하게 된다. 많은 연구 끝에 그는 인도, 이란, 그리고 유럽의 민족들이 한 민족에서 갈라져 나왔다는 결론을 얻었다. 그때부터 인도유럽어족에 대한 연구가 착수되어 수많은 언어들이 모두 같은 뿌리를 가진 언어라는 것이 확인되었고, 이 언어들을 비교하여 더 논리적이고 체계적으로 문법, 발음법 등이 정리될 수 있었다. 존스의 먼치킨성이 아니었으면 지금까지도 몰랐을 것이다.
3 문법적 특징
'인도'유럽어라고 해서 영어와 산스크리트어가 같아 보이리라 착각하면 안된다. 그 정도 경지가 되려면 이미 인도유럽어를 언어학적으로 '어느 정도' 공부해 본 사람만 될 수 있는 경지.
예를 들 수 있는 공통점으로는
(산) Piter: 아버지
(라) pater: 아버지
(영) father: 아버지
(에스페란토) patro: 아버지[5]
누구나 다 아는 이 어족의 큰 특징은 성수에 따른 굴절[6]이 많다는 것.[7]
단 언어의 특성은 시간이 지나면서 변화하기 때문에 인도-유럽 어족이지만 굴절성이 많이 퇴색된 언어도 찾아볼 수 있다. 대표적으로 영어나 아프리칸스어 등이 있다.
인구어의 명사의 변화가 얼마나 복잡한지 느껴보고 싶다면 현대의 메이저 언어 중에서는 러시아어를 배워 보기를 권한다. 어학의 헬게이트를 느낄 수 있을 것이다.[8]. 이보다 더 복잡한 것도 건드려 보고 싶다면? 싱할라어나 아르메니아어, 체코어 같은 마이너 언어나 전통적인 고전어들이 있다. 고대 그리스어, 산스크리트어, 라틴어... 일단 라틴어/동사 활용이나 라틴어/명사 변화 문서를 보고 그 방대함을 직접 느껴보는 것도 좋을 것이다.
그런데 충격적인 것은, 고전어들만 모아서 보면 라틴어는 오히려 쉬운 편에 드는 언어라고 한다.
영어를 배우는 학생들은 영어의 동사변화(have, has, had)가 어렵다고 짜증내는데, 영국 바로 밑에 있는 프랑스어를 봐라.
Avoir(have)[9]
=ai as a avez avons ont avais avait aviez avions aient eu aurai aura aurez aurons auront aurais auras auriez aurions auraeint ayant aie aies ait ayons ayez aient eus eut eûmes eûtes eurent[10]
그리고 상당히 많이 단순화된 현대 그리스어를 보길.
Έχω (have)
=έχω, έχεις, έχει, έχουμε, έχετε, έχουν, είχα, είχες, είχε, είχαμε, είχατε, είχαν, έχε, έχετε, έχοντας
그나마 이 동사는 불완전과거와 완전과거가 누락되어있기에 이정도에서 끝났다.
Αγαπώ (love)
=αγαπώ, αγαπάς, αγαπάει, αγαπούμε, αγαπέτε, αγαπούν, αγαπούσα, αγαπούσες, αγαπούσε, αγαπούσαμε, αγαπούσατε, αγαπούσαν, αγάπησα, αγάπησες, αγάπησε, αγαπήσαμε, αγαπήσατε, αγάπησαν, θα αγαπήσω, θα αγαπήσεις, θα αγαπήσει, θα αγαπήσουμε, θα αγαπήσετε, θα αγαπήσουν, αγάπησε, αγάπηστε, αγάπα, αγάπατε, έχω αγαπήσει, έχεις αγαπήσει, έχει αγαπήσει, έχουμε αγαπήσει, έχετε αγαπήσει, έχουν αγαπήσει, αγαπώντας ㄷㄷㄷ
그리고 아르메니아어를 보면...
սիրել (love)
= սիրող, սիրում, սիրելիս, սիրելու, սիրել, սիրած, սիրում եմ, սիրում ես, սիրում է, սիրում ենք, սիրում եք, սիրում են, սիրում էի, սիրում էիր, սիրում էր, սիրում էինք, սիրում էիք, սիրում էին, սիրելու եմ, սիրելու ես, սիրելու է, սիրելու ենք, սիրելու եք, սիրելու են, սիրեցի, սիրեցիր, սիրեց, սիրեցինք, սիրեցիք, սիրեցին, սիրեմ, սիրեի, սիրեիր, սիրեր, սիրեինք, սիրեիք, սիրեին, կսիրեմ, կսիրես, կսիրի, կսիրենք, կսիրեք, կսիրեն, կսիրեի, կսիրեիր, կսիրեր, կսիրեինք, կսիրեիք, կսիրեին, սիրի՜ր, սիրեgե՜ք, մի՜ սիրիր, մի՜ սիրեք, պիտի սիրեմ, պիտի սիրես, պիտի սիրի, պիտի սիրենք, պիտի սիրեք, պիտի սիրեն, պիտի սիրեի, պիտի սիրեիր, պիտի սիրեր, պիտի սիրեինք, պիտի սիրեիք, պիտի սիրեին, սիրել եմ, սիրել ես, սիրել է, սիրել ենք, սիրել եք, սիրել են, սիրել էի, սիրել էիր, սիրել էր, սիրել էինք, սիրել էիք, սիրել էին, սիրելու էի, սիրելու էիր, սիրելու էր, սիրելու էինք, սիրելու էիք, սիրելու էին 으악
고전 라틴어의 경우는......
amare (love)
= amo, amas, amat, amamus, amatis, amant, amabo, amabis, amabit, amabimus, amabitis, amabunt, amabam, amabas, amabat, amabamus, amabatis, amabant, amavi, amavisti, amavit, amavimus, amavitis, amaverunt, amavero, amaveris, amaverit, amaverimus, amaveritis, amaverint, amaveram, amaveras, amaverat, amaveramus, amaveratis, amaverant, amor, amoris, amatur, amamur, amamini, amantur, amabor, amaberis, amabitur, amabimur, amabimini, amabuntur, amabar, amabaris, amabatur, amabamur, amabamini, amabantur, amem, ames, amet, amemus, ametis, ament, amarem, amares, amaret, amaremus, amaretis, amarent, amaverim, amaveris, amaverit, amaverimus, amaveritis, amaverint, amavissem, amavisses, amavisset, amavissemus, amavissetis, amavissent, amer, ameris, ametur, amemur, amemini, amentur, amarer, amareris, amaretur, amaremur, amaremini, amarentur, ama, amato, amator, amate, amatote, amanto, amantor, amare, amavisse, amatus esse, amaturus esse, amari, amatus iri, amans(amantis), amandus.[11]
정신이 다 혼미해진다.
라틴어에 뿌리를 두고 있지만, 라틴어에 비하면 아주 간결한 스페인어를 보면
amar (love)
= amo, amas, ama, amamos, amáis, aman, amás, amaba, amabas, amaba, amábamos, amabais, amaban, amabas, amé, amaste, amó, amamos, amasteis, amaron, amaste, amaré, amarás, amará, amaremos, amaréis, amarán, amarás, amaría, amarías, amaría, amaríamos, amaríais, amarían, amarías, ame, ames, ame, amemos, améis, amen, ames, amara, amaras, amara, amáramos, amarais, amaran, amaras, amase, amases, amase, amásemos, amaseis, amasen, amases, amare, amares, amare, amáremos, amareis, amaren, amares, ama, ame, amemos, amad, amen, amá[12]
어려운 인도유럽어족만 보았으니 이제 희망을 갖기 위해 쉬운 인도유럽어족도 보자.
네덜란드어는 독일어에 비해 많이 간결화 되어 아래와 같은 활용만 남았다. 그래도 영어보다 많다
loven (love)
= loven, loof, looft, loofde, loofden, love, loofend, geloofd
같은 게르만어인 노르웨이어도 간결하다. (아래는 뉘노르스크)
elske (love)
= elskast, elskar, elska, elskande, elsk
에스페란토는 영어보단 활용이 많지만 불규칙 활용이 없어서 배우기는 쉽다.[13]
ami (love)
= amas, amis, amos, amu, amus
SVO, 즉 주어, 동사, 목적어 순으로 오는 어순이 인도유럽어족의 특징으로 아는 사람도 있지만 이는 잘못이다.[14] '현대 인도유럽어족 언어' 중에서 인도이란어파가 아닌 언어들로 제한하면 어느 정도 맞는 말이지만... 라틴어만 해도 SOV였다[15]. 굴절이 각 단어의 문법적 기능을 보여주었기 때문. 산스크리트어도 이와 비슷하다. 그러던 것이 굴절이 약해지면서 SVO로 바뀌었다.[16] 그렇지만 힌디어를 비롯한 아시아 지역의 인도유럽어들 대부분은 유럽 지역의 인도유럽어들과 다르게 지금도 SOV 어순을 유지하고 있다. 덧붙여 게르만어파, 발트슬라브어파, 인도이란어파, 그리스어 등에서는 형용사가 피한정 명사의 앞에 놓이는 반면,[17] 이탈리아어파, 켈트어파 등에서는 형용사가 피한정 명사의 뒤에 놓인다.
4 분류
4.1 원시인구어
태초의 조어로, 모든 인도-유럽어족 언어의 뿌리다. 항목 참조.
4.1.1 CENTUM, SATEM
위의 인도유럽어족 표 가장 위에, 원시인구어 바로 밑에 있는 두 갈래다.
1000px[18]
인도-유럽어족 언어들의 1~10, 100을 뜻하는 수사들을 비교한 표다. 표를 보면 다른 건 다 비슷한데, 100이 좀 다르다. 이탈리아어파에 속하는 라틴어와 프랑스어는 cent로 시작하고, 게르만어파에 속하는 독일어와 영어는 hund가 들어가며, 인도이란어파에 속하는 벵갈어와 페르시아어에서는 sa다. 인도유럽어족의 연구가 시작된 초기에 그림의 법칙이 발견되면서, 100을 뜻하는 단어의 세 가지 갈래 중에서 cent~와 hund~는 같은 뿌리에서 나왔음을 밝혀냈으나, 인도이란어파에서 왜 sa~ 소리가 들어가는지에 대해서는 별개의 설명이 필요했다. 그래서 어학자들은 인도유럽어족을 100을 지칭하는 단어에 따라서 크게 CENTUM과 SATEM으로 나눴다.
{kind=link}
이런 구분이 생긴 이유는 사실 원시인구어의 혓바닥소리가 세 종류로 나뉘어 있었기 때문이라고 추정된다.
- 경구개음 - *ḱ・*ǵ・*ǵʰ
- 연구개음 - *k・*g・*gʰ
- 양순연구개음 - *kʷ・*gʷ・*gʷʰ
즉 CENTUM어에서는 이 셋 중 경구개음과 연구개음이, SATEM어에서는 이 셋 중 연구개음과 양순연구개음이 통합되었고, SATEM어에서 경구개음이 마찰음으로 변했다고 설명하는 것이다.
위키 백과의 CENTUM과 SATEM을 사용하는 지역을 나타낸 지도. 파란색이 CENTUM, 빨간색이 SATEM이다. 위키백과의 지도 이외에도 구글에 centum satem map이라 치면 다양한 자료를 찾을 수 있으니 궁금하면 찾아보도록 하자.
물론 오늘날에 와서는 켄툼어군과 사텀어군을 유효한 분류군으로 인정하지 않는 학자들도 나타나고 있다
4.1.1.1 세부 분류
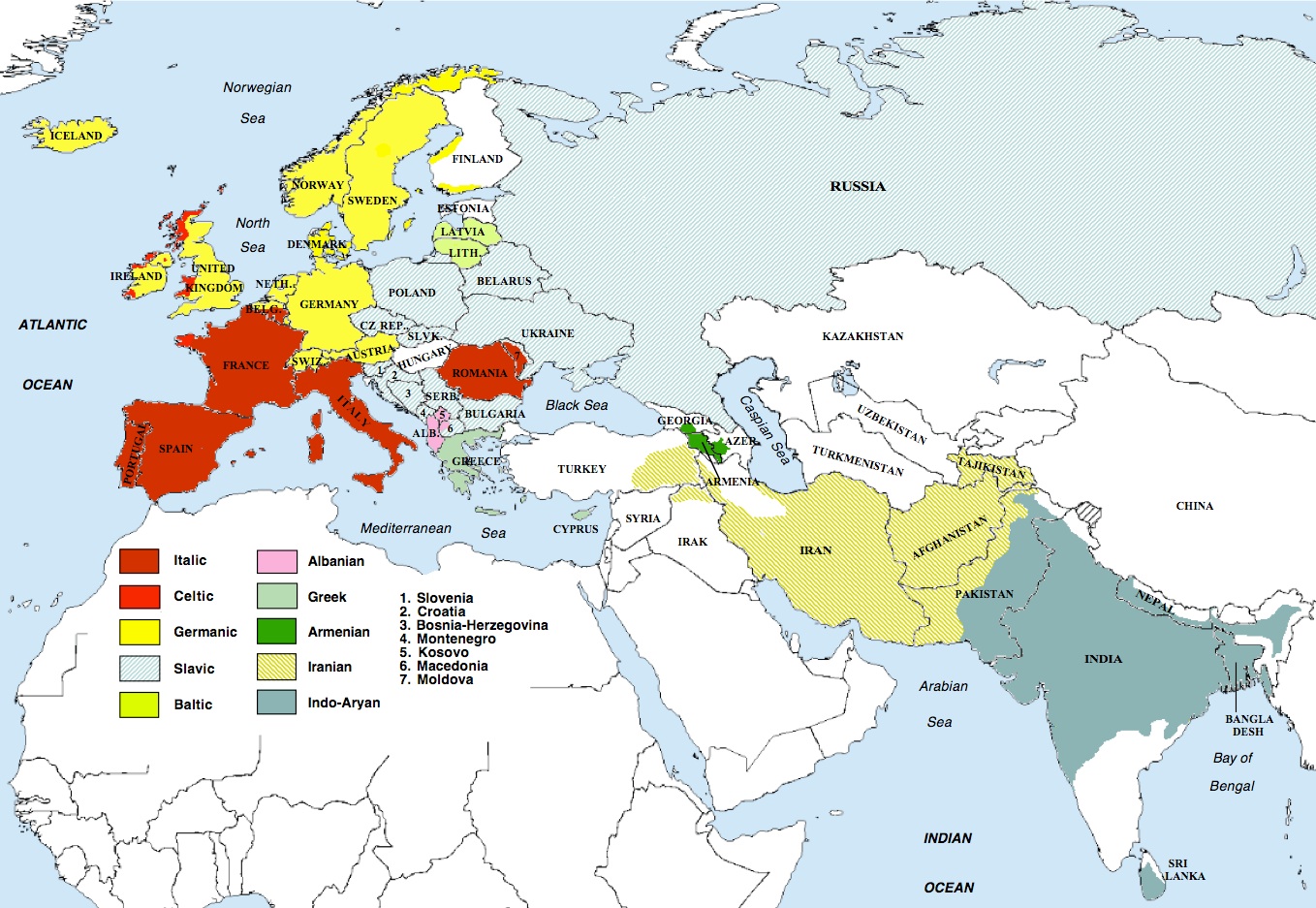
이 중 발트어파와 슬라브어파는 공유하는 특징이 많아 발트슬라브어파라는 통합된 어족으로 여겨지기도 한다. 그리스어, 아르메니아어, 알바니아어는 그 자체로 하나의 어족을 이룬다.
- ↑ 언어 수 기준으로 하면 반투어파가 포함되어 있는 니제르콩고어족
- ↑ 세계에서 두 번째로 큰 어족은 바로 이 어족.
- ↑ 고대 로마에서 "제우스의" 또는 "주피터의"라는 뜻을 갖는 요비스(Iovis), 요비우스(Iovius)라는 인명이 여기서 유래되었다. 로마인 이야기 13권에서는 디오클레티아누스와 공동황제였던 막시미아누스가 은퇴용 별장을 지을 때 별장 이름에 요비우스라는 이름을 붙였다고 언급한다. 물론 별장 이름에 하나님이나 여호와, 또는 예수 그리스도라고 붙인 예가 없음을 들면서 다신교와 일신교의 차이점을 언급하였다.
- ↑ =주피터
- ↑ 인공어이므로 당연히 인도유럽어족에 포함되지 않는다.
- ↑ 명사류는 곡용, 동사류는 활용이라고 한다. 그러므로 성수에 따른 굴절은 곡용.
- ↑ 독일어의 경우에 성-수(남성단수/여성단수/중성단수/복수)*격(총 4개의 격. 영어보다 1개 더 많다.)=16종의 기본적인 명사곡용의 범주가 있다. 많다고? 산스크리트어의 경우에는 수(단수/쌍수/복수)*성(남성/여성/중성)*격(총 8개의 격)=72종이다... 라틴어의 경우는 동사가 10시제 6인칭(1,2,3인칭 * 단,복수) 60개, 명사가 단복수 6격으로 12개의 형태를 갖고 있는데, 이런 것이 동사에서 5개 명사에서 5개가 존재하며 거기에다가 또다시 불규칙 변화하는 단어가 있다. 동사는 공통적인 규칙을 잡아 주면 외우기는 의외로 쉽지만 명사는 그런 것도 없기 때문에 후새드
- ↑ 다만 러시아어문서에 나와있듯이 러시아어 격변화가 항간에 알려진 것보다 오히려 수월하다는 의견이 많다
사실 격변화는 의외로 규칙이 많아서 외우기 쉽지만 어려운건 격변화를 활용하는 것이다. - ↑ 물론 같은 대응 표현을 찾으면 영어에서도 완료, 미래의 조동사를 알아야 한다. 하지만 분리된 동사를 덧붙여서 사용하는 것이므로 프랑스어보다 상대적으로 훨씬 단순하다.
- ↑ 프랑스어 또한 영어와 마찬가지로 굴절이 대다수 제거되었기 때문에 이 정도밖에 나오지 않고, 불규칙 동사의 굴절도 다른 불규칙 동사들과 겹치는 활용형 어미가 많아 그나마 프랑스어의 굴절은 다른 언어들에 비해 그나마 쉬운 편.
- ↑ 위 목록에는 수동 완료 형태를 생략했다. 직설법 수동 완료, 접속법 수동 완료까지 제대로 다 쓰면 위 목록만큼의 분량이 더 나온다. ㅎㄷㄷ
- ↑ 완료형을 더하면 이만큼 더 나온다. 영국이 무적함대를 이겨내지 못했다면,,,,,
- ↑ 애초에 굴절어가 아니라 교착어다.
- ↑ 같은 어족에 속하는 언어들이라고 해서 어순이 다 같은 건 아니다. 인도유럽어족에 속하는 언어들 가운데서도 인도이란어파 언어들은 오히려 한국어와 비슷한 SOV 어순을 나타내며, 중국어와 티베트어는 같은 중국티베트어족에 속하지만 어순이 서로 다르다.
- ↑ 정확히 말하면 라틴어는 일단은 정해진 어순이 없지만 그 중에서 자주 쓰이는 어순이 SOV였던 것이다. 한 가지 규칙을 얘기하면, 일단 라틴어 문장에선 맨 처음에 놓인 단어가 제일 강조되며, 그 다음엔 맨 마지막에 놓인 단어도 상당한 강도를 띈다고 한다.
- ↑ 주어와 목적어를 구분지어주는 형태소가 약화, 소실됨에 따라 주어와 목적어는 동사를 중심으로 어느 위치에 놓이느냐에 따라 구별하게 되었다.
- ↑ 예외적으로 폴란드어(발트슬라브어파), 페르시아어(인도이란어파)에서는 형용사가 피한정 명사의 뒤에 놓인다. 다만 페르시아어는 얘기가 좀 다른데, 페르시아어에서는 형용사 변화가 아예 소멸한(...) 관계로 영어로 예를 들면 black mountain이 아니라 mountain which is black과 같은 형태만 남아있다. (which is에 해당되는 페르시아어 표현이 현대로 오면서 극단적으로 축약되서 에저페가 되었다.)
- ↑ - 조승연의 오리진보카 PIE
- ↑ 인도 남부(드라비다어족 언어를 주로 사용함)와 부탄처럼 벵골 이동의 산악지대 제외. 이 지역에서는 종카어나 마니푸르어처럼 오히려 중국티베트어족의 티베트어와 유사한 언어들이 더 많이 쓰인다.
- ↑ 사용자가 적은 편이다.
- ↑ 인공어라 어족을 따로 구별하진 않지만, 인도유럽어족 언어를 바탕으로 만들어졌다.
어째 맨날 취소선 당하는 신세가 된 거지?